

Authors
Machine learning has long permeated all areas of human activity. It not only plays a key role in the recognition of speech, gestures, handwriting and images – without machine learning it would be difficult to imagine modern medicine, banking, bioinformatics and any type of quality control. Even the weather forecast cannot be made without machines capable of learning and generalization.
I would like to warn about, or dispel, some of the misconceptions associated with the use of ML in the field of cybersecurity.
Myth №1: Machine learning in information security is a novelty
For some reason, discussion of artificial intelligence in cybersecurity has become all the rage of late. If you haven’t been following this theme over the longer term, you may well think it’s something new.
A bit of background: one of the first machine learning algorithms, the artificial neural network, was invented in the 1950s. Interestingly, at that time it was thought the algorithm would quickly lead to the creation of “strong” artificial intelligence. That is, intelligence capable of thinking, understanding itself and solving other tasks in addition to those it was programmed for. Then there is so-called weak AI. It can solve some creative tasks – recognize images, predict the weather, play chess, etc. Now, 60 years later, we have a much better understanding of the fact that the creation of true AI will take years, and what today is referred to as artificial intelligence is in fact machine learning.

Source: http://dilbert.com/strip/2013-02-02
When it comes to cybersecurity, machine learning is nothing new either. Algorithms of this class were first implemented 10-12 years ago. At that time the amount of new malware was doubling every two years, and once it became clear that simple automation for virus analysts was not enough, a qualitative leap forward was required. That leap came in the form of processing the files in a virus collection, which made it possible to search for files similar to the one being examined. The final verdict about whether a file was malicious was issued by a human, but this function was almost immediately transferred to the robot.
In other words, there’s nothing new about machine learning in cybersecurity.
Myth №2: Machine learning in cybersecurity is straightforward – everything’s already been thought of
It’s true that for some spheres where machine learning is used there are a few ready-made algorithms. These spheres include facial and emotion recognition, or distinguishing cats from dogs. In these and many other cases, someone has done a lot of thinking, identified the necessary signs, selected an appropriate mathematical tool, set aside the necessary computing resources, and then made all their findings publicly available. Now, every schoolkid can use these algorithms.
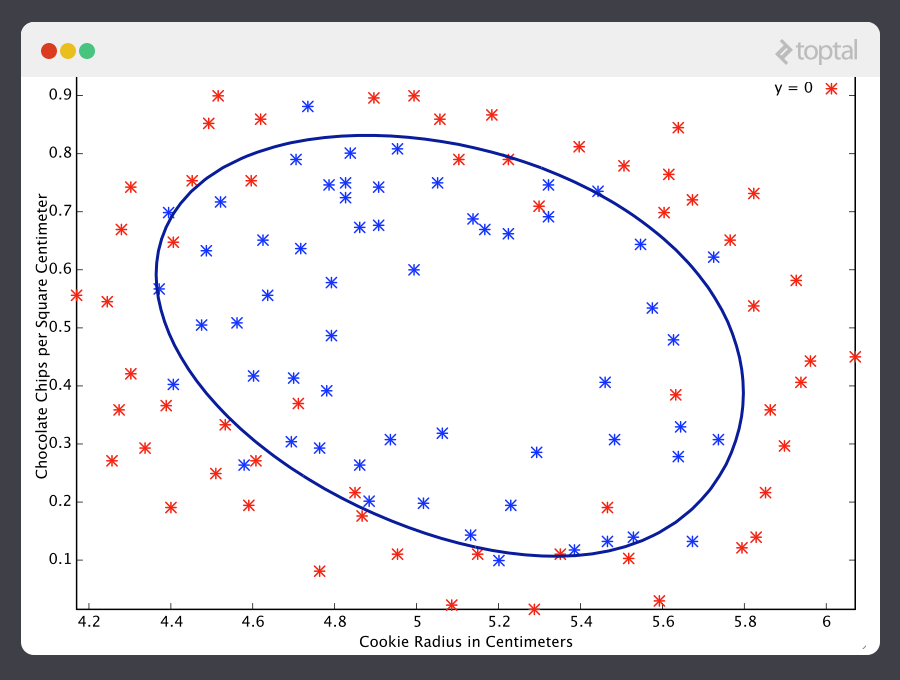
Machine learning determines the quality of cookies by the number of chocolate chips and the radius of the cookie
Source: http://simplyinsight.co/2016/04/26/an-introduction-to-machine-learning-theory-and-its-applications-a-visual-tutorial-with-examples/
This creates the false impression that the algorithms already exist for malware detection too. That is not the case. We at Kaspersky Lab have spent more than 10 years developing and patenting a number of technologies. And we continue to carry out research and come up with new ideas because … well, that’s where the next myth comes in.
Myth №3: Machine learning – do it once and forget about it
There is a conceptual difference between malware detection and facial recognition. Faces will remain faces – nothing is going to change in that respect. In the majority of spheres where machine learning is used, the objective is not changing with time, while in the case of malware things are changing constantly and rapidly. That’s because cybercriminals are highly motivated people (money, espionage, terrorism…). Their intelligence is not artificial; they are actively combating and intentionally modifying malicious programs to get away from the trained model.
That’s why the model has to be constantly taught, sometimes even retrained from scratch. Obviously, with rapidly modifying malware, a security solution based on a model without an antivirus database is worthless. Cybercriminals can think creatively when necessary.
Myth №4: You can let security software learn on the client side
Let’s say, it processes the client’s files. Most of them will be clean, but some will be malicious. The latter are mutating, of course, but the model will learn.
However, it doesn’t work like that, because the number of malware samples passing through the computer of an average client is much smaller than the amount of malware samples collected by an antivirus lab system. And because there will be no samples for learning, there will be no generalization. Factor in the “creativity” of the virus writers (see the previous myth) and detection will fail, the model will start recognizing malware as clean files and will “learn the wrong things.”

Myth №5: It’s possible to develop a security solution that’s based solely on the ML model, without other detection methods
Why use multi-level protection based on different technologies? Why not put all your eggs in one basket if that basket is so smart and advanced? One algorithm is enough to solve everything. Right?
The thing is most malware belongs to families consisting of a large number of modifications of one malicious program. For example, Trojan-Ransom.Win32.Shade is a family of 30,000 cryptors. A model can be taught with a large number of samples, and it will gain the ability to detect future threats (within certain limits, see Myth №3). In these circumstances machine learning works well.
However, it’s often the case that a family consists of just a few samples, or even one. Perhaps the author didn’t want to go into battle with security software after his “brainchild” was immediately detected due to its behavior. Instead, he decided to attack those who had no security software installed or those who had no behavioral detection (i.e., those who had put all their eggs in one basket).
These sorts of “mini-families” cannot be used to teach a model – generalization (the essence of machine learning) is impossible with just one or two examples. In these circumstances, it is much more effective to detect a threat using time-tested methods based on the hash, masks, etc.
Another example is targeted attacks. The authors behind these attacks have no intention of producing more and more new samples. They create one sample for one victim, and you can be sure this sample will not be detected by a protection solution (unless it is a solution specifically designed for this purpose, for example, Kaspersky Anti-Targeted Attack Platform). Once again, hash-based detection is more effective.
Conclusion: different tools need to be used in different situations. Multi-level protection is more effective than a single level – more effective tools should not be neglected just because they are “out of fashion.”
The problem of Robocop
And one last thing. This is more of a warning than a myth. Researchers are currently paying more attention to what mistakes complex models are making: in some cases, the decisions they take, cannot be explained from the point of view of human logic.
Machine learning can be trusted. But critical systems (the autopilot in planes and automobiles, medicine, control services, etc.) usually have very strict quality standards; formal verification of software programs is used, while in machine learning, we delegate part of the thought process and responsibility to the machine. That’s why quality control of a model needs to be conducted by highly respected experts.
Five myths about machine learning in cybersecurity
Table of Contents
- Myth №1: Machine learning in information security is a novelty
- Myth №2: Machine learning in cybersecurity is straightforward – everything’s already been thought of
- Myth №3: Machine learning – do it once and forget about it
- Myth №4: You can let security software learn on the client side
- Myth №5: It’s possible to develop a security solution that’s based solely on the ML model, without other detection methods
- The problem of Robocop
From the same authors




In the same category















n
The five strawmen of machine learning in *information* security (You gotta love it when someone complains about a buzzword just after using a more meaningless one the title).
Strawman #1: machine learning is here since the 50s, we’ve used it for ages
Although algorithms and strategies of machine learning have been here for quite a while, the hardware to harness it properly, in real life scenarios, is relatively new. The capacities of data and abilities to meticulously collect and categorize it are pretty new. The inclusion of machine learning as part of the actual detection engine (as claimed by ng-av) was never part of traditional av, which limit the use of ML to backend and sample processing alone, with low impact on actual detection algorithms (which are still mostly signature based).
Strawman #2: If there’s no publicly available solution, the problem cannot be solved
First – All fields of machine learning you’ve namely mentioned’s best solutions are is being daily improved, and are mostly closed-source. obviously, there may be some open-source toy projects but that’s all those are.
Second – what you’re “debunking” is the exact opposite of what ng-av startups are saying: they’re **not** saying these are publicly solved problems and traditional avs just won’t use them. They’re saying solving those problems is a difficult problem they’ve solved *internally*, making those solutions their IP and sole reason to exist in the first place.
Strawman #3: My field of expertise is a lot more complex then any other, thus I cannot be replaced with a machine!
the basic claim that “malware are not faces” is ridiculous. The malware classification problem is a lot simpler than a lot of image recognition, speech recognition and other ‘traditional ML problems”. faces may not change; roads, speech, etc will.
Additionally, the claim that the ML malware classification solution won’t need maintenance was a. never heard from ng-av and b. counter-productive to a startup that want’s to justify it’s prolonged existence.
Strawman #4: client side learning? then they’re not doing anything else!
client side learning does not mean (unless you’re biased towards traditional av, that is 😉 ) all of your data comes from the client’s side. It means that on top of traditional backend sample processing (as performed by traditional avs for years), there’s *even more data* that is *specific to every client’s needs* and *represents the client’s environment better*. Its not that ng-av has less data – it’s that it has more white data.
Strawman #5: Not every machine learning algorithm fits every task, so none does!
The title is quite vague, so i’ll address the specifics:
“These sorts of “mini-families” cannot be used to teach a model – generalization (the essence of machine learning) is impossible with just one or two examples.”
This case may be true for clustering algorithms, but for other ML algorithms this is plain wrong, generalization is not required to be on every family in today’s malware space, generalization can be (and in some cases better be) between multiple malware families. A good SVM model, for example, will generalize *all* malware samples.
“They create one sample for one victim … Once again, hash-based detection is more effective.”
This is straight-out ridiculous. If there’s one sample for one victim, the goal should be to detect that sample *before* you encounter it in the wild. a hash or similar may be enough for post-mortem cleanup but it’ll do squat for detection.
“Conclusion: different tools need to be used in different situations. Multi-level protection is more effective than a single level – more effective tools should not be neglected just because they are “out of fashion.””
This is correct, but different tools does not dictate non-ML (you can use ML for static detection and you can use it for behaviors, and there you have more layers), or does not mean ng-av startups don’t invest in some traditional approaches (that’s just isn’t the selling point).
Alexey Malanov
As noted in the text, more than 10 years of machine learning algorithms are used in Kaspersky Lab to create antivirus records that are capable of generalizing on the client side. And that’s where the high level of detection – confirmed by independent tests – comes from. We could argue all day long about “claims of ng-av”, but we prefer the results of independent tests. But those startups that you mentioned, unfortunately, avoid participating in these tests, and because of that the quality of their ‘kung fu’ is difficult to assess.
charlie
I smell *cough* *cough* a vendor with name starting with CY and ending with LANCE behind first lengthy comment.
>>This is straight-out ridiculous. If there’s one sample for one victim, the goal should be to detect that sample *before* you encounter it in the wild. a hash or similar may be enough for post-mortem cleanup but it’ll do squat for detection.
Can ANY ML based AV engine guarantee to catch this one sample proactively ?? Atleast with hash based detection we can guarantee we will catch that specific sample no matter what if it’s in same form.
Tjusanto Ongkorahardjo (Agus)
very good create