

Authors
If you read my previous blogpost Hunting APTs with YARA then you probably know about the webinar we conducted on March 31, 2020, showcasing some of our experience in developing and using YARA rules for malware hunting.
In case you missed the webinar – or if you attended and want to re-watch it – you can find the recording here:

As requested by many of you, we are also making the slides available through SlideShare:

Unfortunately, we were forced to cut short the broadcast as we were running out of time. Nevertheless, we received a number of interesting questions and as I promised, I’ll try to answer them below. Thanks to everyone who participated and I appreciate all the feedback and ideas!
YARA webinar – questions
- Can you share the presentation? (multiple requests)
Sure, please find the link above for SlideShare.
- Hi Costin! what is the point of writing a rule on the exploit and not about the vulnerability? (from Ari)
Hi Ari, hope you guys are doing well! In this case, we are trying to hunt an unknown 0day exploit and, therefore, don’t know which vulnerability it exploits. The only things we can hunt for are the artifacts that the exploit developer left in older versions of the same exploits (in this case, Silverlight). For more details, please see our blogpost: The mysterious case of CVE-2016-0034: the hunt for a Microsoft Silverlight 0-day.
- I’ll add an xml-based switch to show Imphash in lowercase, in pestudio! (from Marc)
Thanks Marc, appreciated. And sorry for mispronouncing your last name! Everyone, in case you aren’t already using Pestudio for your initial malware assessment, go check it out.
- “Your italian is pretty good man / your italian is not so bad / Your italian is great 🙂 ” – various amici
Thank you! Perhaps not surprisingly, Romania used to be a Roman colony 2000 years ago, which is why our languages are so similar. Wishing you guys all the best, stay safe and stay healthy!
- When you are looking or other languages, does the “pe.language” catch all hexbyte formats? (I.e. UTF-8 and UTF-16 will show mandarin characters in different hex bytes) (from Jono)
That’s a good question. In reality, pe.language actually cycles through all the resources in the PE file and returns true if the language of at least one resource matches the one you are looking for. So it isn’t really searching for any characters in the file, only using the metadata from the resource section.
- Can please explain “not for all i” in criteria – from Rohit, referring to the generic YARA rule from example 3
Indeed, this is one tricky rule. Just to make it easier, I’m showing the solution below:
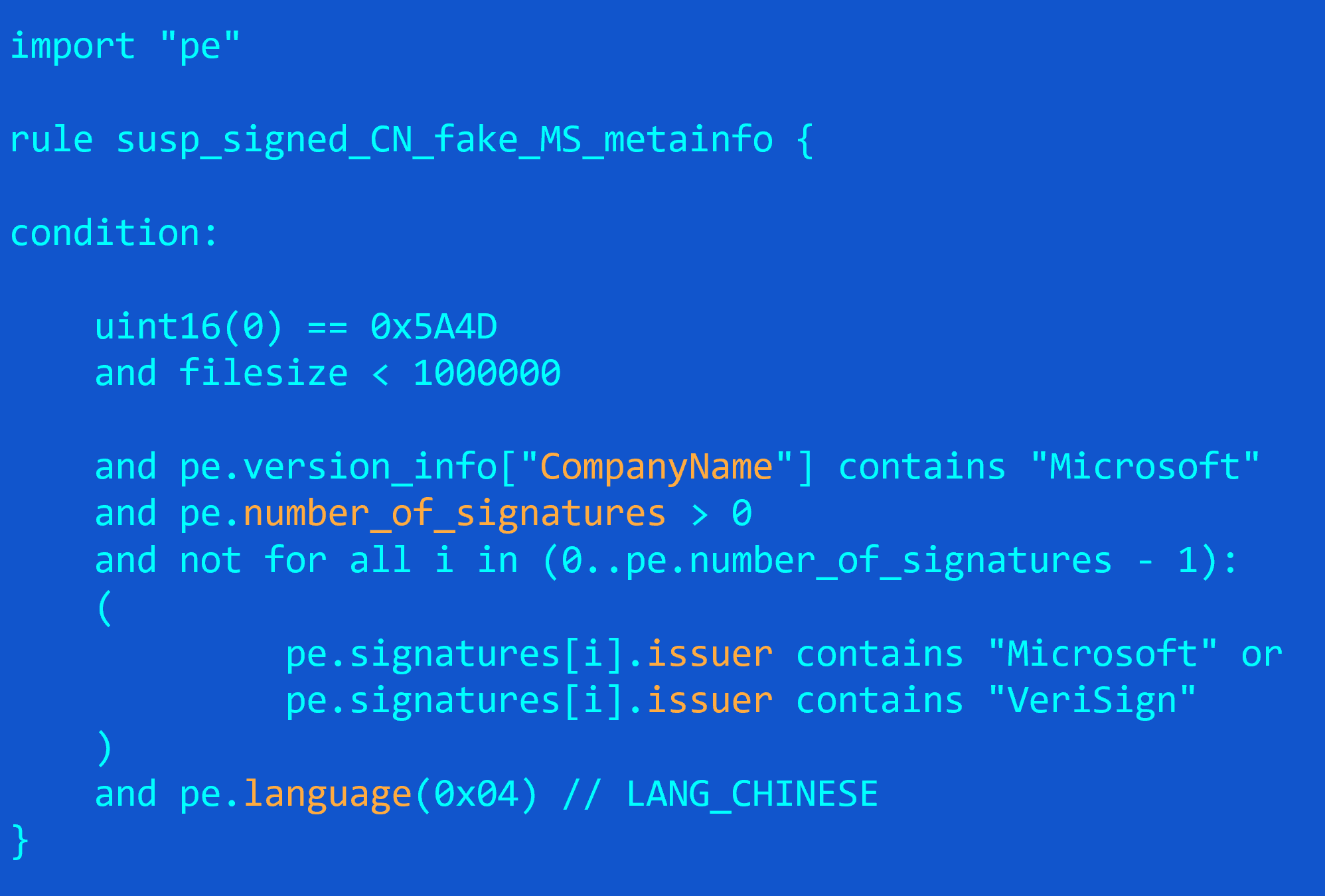
Basically, the rule works as follows: first, the version_info structure field named “CompanyName” should contain “Microsoft”, which means the file is claiming to be from Microsoft. Secondly, it needs to be signed with a digital certificate, so pe.number_of_signatures should be larger than 0. Finally, we check if there is at least one issuer for all the certificates used to sign the file that is not Microsoft nor VeriSign. Why “not for all”? Well, it’s a reverse logic – for all the certificates, we want to make sure the signatures are either from Microsoft or VeriSign. If at least one sig is found that is not from these two, the file is suspicious. Another way to do this would be to keep “and for all” and apply the “not” inside the loop, switching the “or” for an “and”. (because not (a or b) ==not a and not b)
- Do you have any open source database of good and benign files to test against false positives? (from Ramon)
Hey Ramon, thanks for the question! Please go to slide 37 for advice on how to build a benign sample set for QA and false positives testing.
- When you specify the “filesize” attribute within your rule – what denomination do you target? Bytes, Kilobytes, Megabytes etc…? (from James)
By default, the filesize is expressed in bytes, so 200000 would be 200000 bytes. The YARA syntax also supports KB and MB, with KB multiplying by 1024 and MB by 2^.20.
- Would you recommend using the xor modifier now for this stuff? (from John) referring to slide 39:

The example on the right side is from Shamoon2 samples, where some of the strings were XOR’ed by a one-byte key which kept changing from sample to sample. Interestingly enough, Yara has supported the xor modifier since version 3.8 (or so). However, the xor modifier is always applied last, so for our case above, it will work, as the zeroes in the wide strings will be xor’ed as well! Therefore, we need to bruteforce the strings and use them like in the case above if the zeroes are not xor’ed.
- How long does it take to scan your full collection with a normal YARA rule? (from Juan Aleister-Crowley)
The entire Kaspersky malware collection, which is possibly one of the largest in the world, takes between one and two weeks to scan entirely, on a cluster of a few hundred computers. However, in most cases, we resort to scanning subsets, such as recent samples or known APT samples already tagged by our robots, which can take anywhere between a few minutes up to a day or two.
- What is your experience of using matching on the PE Rich Header? (from Axel)
Good question! While in theory the pe module could allow for the creation of rules that match on the decrypted Rich header, we haven’t played much with that. This is however something we’ve explored in connection to the Hades APT attack on the Winter Olympics and the associated false flag that relied on the Rich header from a Lazarus sample.
- What are some best practices around managing a collection of YARA rules? Rules harvested from the web as well as the ones internally developed. Are there any specific tools dedicated to maintaining such a collection? Do you just use Git? (from V)
Hey V, thanks for the question! This is indeed one of the trickiest things and I have to admit that I don’t know of a perfect solution yet. Yes, there are some YARA management frameworks, but I can’t say I’m a big fan of any of them in particular. I do use Git for this purpose, but I also lack a nice visual interface that would allow me to search, edit and run them against samples with one click.
- Better speed if checking the file size before the rules? (from Damien)
That’s a good question. According to Victor, the condition is evaluated by a decision tree, so the order is not necessarily the one that you put in the syntax. To be honest, I do prefer to put the filesize check first, perhaps for “superstitious” reasons 🙂
- Here is a question “5 of ($b*)” means “any 5 of ($b*)” or “first 5 of ($b*)” (from Yerbol)
Indeed, that means any (sub-)group of five $b strings.
- Hi, why is important and good indicator to use PDB paths in a YARA sigs? (from Adrian)
Based on our experience, PDB paths, in particular unique-looking folder names from PDB paths, are very good at detecting future malware from the same author. For example, take the EternalBlue scanner from Omerez that is used by the CobaltGoblin group – it has the following PDB inside:
C:\Omerez\Projects\Eternal Blues\EternalBlueScanner\obj\Release\EternalBlues.pdb
A YARA rule that matches on “C:\Omerez\Projects\” could find other tools from the same author.
If you have any more questions about the YARA webinar, please feel free to drop us a line in the comments box below or on Twitter: @craiu.
P.S. Special note for those trying to do the iOS/MacOS homework – if you write the rules but don’t have access to a platform to run them for hunting purposes, please drop us a note at: yarawebinar [at] kaspersky.com
Thanks and stay safe!
Costin
YARA webinar follow up
From the same authors




In the same category















Anita
Hello 🙂 Thank you for providing this excellent webinar. I have a probably easy-to-answer question about the alternative Yara rule discussed in Question 6 above (regarding the use of “not for all i”). You explain in the answer that (quote):
‘”Another way to do this would be to keep ‘and for all’ and apply the ‘not’ inside the loop, switching the ‘or’ for an ‘and’ (because not (a or b) == not a and not b)”.
Why is it that we do not have to change the “and for all” to “and for any”? Please note that I am new to Yara, so my understanding of it is still very basic!
Thank you for the additional clarification 🙂
Securelist
Hi Anita,
If we add “not” inside the condition in the loop as is, the rule will search for signatures which are not from either Microsoft or Verisign. It will look as follows:
for all
not (contains) and
not (contains)
Indeed, we should replace “for all” with “for any” if we move “not” inside the loop. In that case, the new rule will search for at least one signature that is different from Microsoft or Verisign, even if the file also contains Microsoft or Verisign signatures. Such rule will look as follows:
for any
not (contains) and
not (contains)
Great catch! Thank you for being observant!