

This summer Kaspersky experts took part in the Machine Learning Security Evasion Competition (MLSEC) — a series of trials testing contestants’ ability to create and attack machine learning models. The event is comprised of two main challenges — one for attackers, and the other for defenders. The attacker challenge was split into two tracks — Anti-Malware Evasion and Anti-Phishing Evasion. Even though in our routine work we tend to deal with ML-based protection technologies, this time we decided to step into the attackers’ shoes and chose the offensive tracks. Our Anti-Malware Evasion team consisted of two data scientists — Alexey Antonov and Alexey Kogtenkov — and security expert Maxim Golovkin. In the Anti-Phishing Evasion team there were two more data scientists — Vladislav Tushkanov and Dmitry Evdokimov.
MLSEC.IO Phishing Track
In the phishing track the task was to modify 10 (synthetic) phishing samples (i.e. HTML pages) to convince seven phishing detection models that they were benign. A model was bypassed if it returned a probability of less than 0.1 for each sample. Yet there was a catch: after the modifications the samples had to look the same as before (or to be exact, render screenshots were to have the same hashes for both the original and modified html file). Models were available via an API, meaning that the setting was black-box. To win we had to fool as many models as possible for each sample using the fewest possible number of API queries.
What we did
At first, we thought of attempting a classic model replication attack (see AML.T0005 of MITRE ATLAS), but after we entered the competition we observed that the leader already got the highest possible score using just 343 API calls (with one full upload costing 70 calls). This sort of attack would involve submitting a large number of phishing/non-phishing pages to retrieve model outputs and training “shadow” models of our own, which we would then attempt to bypass offline. However, we did not have the API query budget for that, which probably made the setting a bit more realistic. We, therefore, had to rely upon our domain expertise and pure chance. We started off by submitting several clean (benign) web pages — such as Wikipedia’s — to check what probabilities the models would return. But, while the first three models were quite happy with them, the remaining four consistently generated probabilities way above 0.1. From the API response speed we observed that the models might be ingesting raw HTML without any kind of browser rendering.
Littering the page with invisible text
We composed a simple script to check render hashes and tried our first solution — adding a large hidden chunk of Wikipedia text to the phishing sample, fixing invalid HTML and applying minification. This worked, but only for the first three models. We wondered whether some of the models could be overfitting the provided samples. As we went along, we learned that the last three models often had the same scores, so we only tested our samples on the previous model (likely the most sensitive one) to save API calls.
Obfuscation via byte shift
When working on phishing detection, we, like Rutger Hauer in Blade Runner, had seen things. Phishing payloads hidden in Morse code. Phishing pages consisting almost entirely of screenshots in base64. Actual page text encrypted with ROT13. Drawing on this domain knowledge, we devised our first obfuscation scheme:
- Create a small fake “personal blog” page.
- Take the actual phishing page, shift all the symbols by n and store as a string.
- On page load, shift the symbols back and document.write the result back to the page. However, this turned out to be a bad idea — not only did the shifting process create all kinds of escaping issues, the last three models still sounded alarms on our samples. We added popular header tags, such as <meta>, which somehow led to poorer results on the first three models. It felt like the last three models were unhappy about the large number of HTML tags or, probably, the high-entropy payload string.
Obfuscation via byte integer encoding
We then tried another kind of obfuscation. Instead of shifting, we encoded each byte as an integer number and put the numbers into invisible <img> tags. This fooled the first four models, but not the last three. However, the results were better. We wondered whether or not the last three models reacted strongly to the obfuscator code. Maybe they didn’t like document.write? We submitted an empty page with the obfuscator present and learned that the probabilities were quite low — from 0.074 for the first four models to 0.19 for the remaining three — meaning the phishy JavaScript was not what the models were looking at.
Less tags, more text
We hypothesized that the models somehow took into account character distribution. Considering their probable aversion to HTML tags, we used a big chunk of raw text — an excerpt from the Bible. We added the relevant <meta> to the header and hid chunks of numericized bytes among the verses, like this:
|
1 2 3 4 |
20:18 And he said, Whether [101 49 99 114 117 119 89 79 108 80 78 90 65 83 83 47 56 122 74 74 57 69 104 108 85 67 105 72 106 108] they be come out for peace, take them alive; or whether they [70 50 43 97 107 121 71 68 48 47 104 105 83 86 86 108 107 106 107 48 114 111 49 114 78 83 49 85 118 75] be come out for war, take them alive. |
This worked! Nine pages out of 10 bypassed all seven models, while the 03.html sample was rejected as too large (the maximum size was experimentally determined to be 10 MB). Moreover, all the probabilities were the same:
| 00 | 01 | 02 | 03 | 04 | 05 | 06 |
| 0.02 | 0.02 | 0.02 | 0.02 | 0.084 | 0.087 | 0.087 |
By that time, we still had about 50 API calls left.
Back to base (64)
This obfuscation scheme was highly inefficient, each byte at least quadrupled. 03.html was a monster of a page, weighing 4 MB due to a few high-res base64 encoded images. We dug into the source code and noticed that some of them were duplicated, so we carved them out. The page slimmed down to 1.7 MB. Alas, to make the obfuscated page less than 10 MB, we were forced to radically increase the numbers-to-text ratio. The last three models sounded alarms, probably because they were suspicious of the unusual character count distribution. However, we learned that if we changed the separator from a space to \n, the sample bypassed them, and the models did at least some kind of processing line by line. In addition to being inefficient, the pages loaded very slowly. So slow in fact that the grading system returned a screenshot equality check failure for 03.html with byte-to-integer obfuscation. We were wary of using base64 at first, as it was commonly used in the original samples, but in the dying hours of the competition, we decided to give it a try and placed base64 chunks among the cloak text:
|
1 2 3 4 5 6 7 |
PGhlYWQ+PG1ldGEgY2hhcnNldD11dGYtOD48bWV0 1:2 And the earth was without form, and void; and darkness was upon YSBjb250ZW50PSJ3aWR0aD1kZXZpY2Utd2lkdGgs the face of the deep. And the Spirit of God moved upon the face of the IGluaXRpYWwtc2NhbGU9MS4wIiBuYW1lPXZpZXdw waters. b3J0PjxtZXRhIGNvbnRlbnQ9IlNpdGUgRGVzaWdu |
It worked! The page loading time also decreased sharply, and we were able to finally receive the full score for 03.html with the following model outputs:
| 00 | 01 | 02 | 03 | 04 | 05 | 06 |
| 0.017 | 0.017 | 0.017 | 0.017 | 0.072 | 0.076 | 0.076 |
Thus, we were able to fool the models and took first place in the anti-phishing track.
MLSEC.IO Anti-Malware Track
The anti-malware track consisted of two parts. The defensive part was about creating anti-malware models resistant to adversarial attacks. Note that these models must meet certain quality requirements regarding FPR/TPR on some hidden dataset, so it is impossible to create a model that would simply detect all files. The task was to provide six models for attacking.
The adversarial part was about modifying 50 malicious files in such a way as to bypass as many defense track models as possible (by making them appear benign). At the same time, the modified files were tested by the sandbox contest system. The files were to behave exactly the same way as the original malicious objects.
In the attack competition there was an API allowing us to get model predictions (0 for clean files, 1 for malicious ones). It was also possible to send files for a complete test that included not only a model classification check, but also a sandbox behavior comparison against the originals.
Dataset
The organizers did not post a dataset for the training models (which might have been useful in both the defensive and attacking parts for building and experimenting with models). However, they suggested using the Ember dataset, which has about 200,000 pre-calculated feature vectors for labeled clean and malware files (100,000 for each class), as well as a large number of unlabeled vectors. The dataset offers quite a powerful set of features, including byte distribution histograms in the file and entropy, header signs, file sections, information about the file’s readable strings, and more.
First Experiments
The contest topic strongly overlapped with our recent article about attacks on ML models. So we decided to apply the techniques discussed in the article. First, we trained a neural network model on the Ember dataset using its labeled part (assuming that the defenders would do the same). Then, for each target malicious file, we began to iteratively change certain features (specifically, the byte histograms and the string features) using gradient steps, thereby decreasing the probability of “bad” label prediction by the model. After several steps, a new set of features was obtained. Next we had to create a modified file that would have such features. The modified file could be constructed either by adding new bytes to the end of the file (increasing the overlay) or by adding one or more sections to the end of the file (before the overlay).
Note that this file modification method significantly reduced the probability of files getting classified as malware — not only for the attacked neural network, but also for other completely different architecture models we trained on the same dataset. So the first results of the local testing experiments were quite impressive.
Yet five out of six contest models continued detecting those modified files, just like the originals. The only “deceived” model, as it turned out later, was simply too bad at detecting malicious files and easily confused by almost any modification of the original. There were two possibilities: either the participating models should use none of the features we changed for the attack at all, or heuristics should be used in these models to neutralize the effect of the changes. For example, the basic heuristic proposed by the organizers was to cut off the file’s last sections: this way the added sections effect would be simply ignored.
What features are important for the contest models?
Our further steps:
-
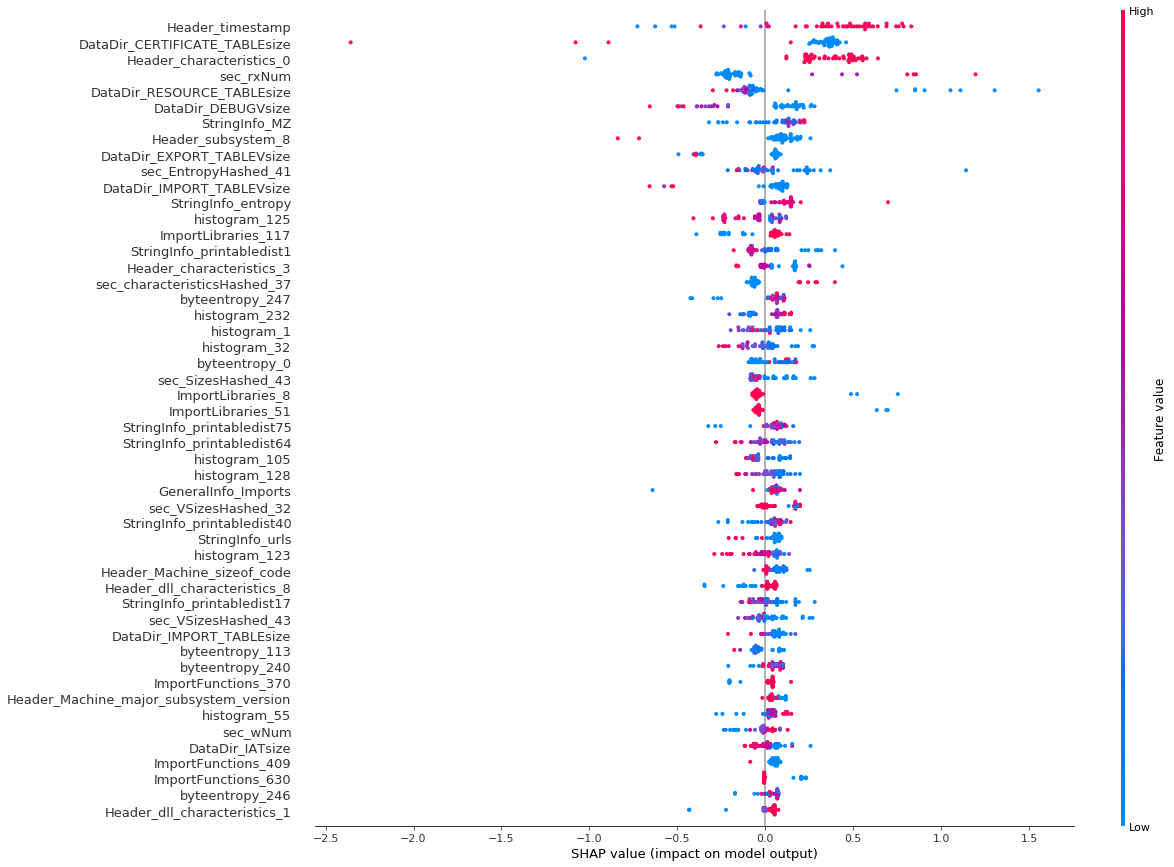
We tried to find out what features were important for the classifiers. To do this we trained a boosting model on the proposed dataset. Then we proceeded to measure the importance of individual features for target malicious files using Shapley vectors. The picture below shows the features affecting the classification results the most. The color represents the feature value, and the position on the X axis shows whether this value pushes the file into the “clean” or the “malware” zone.

Feature importance for file classification
For example, the timestamp feature has a significant impact on the classifier. The smaller its value (e.g., older file), the more the file is considered to be “clean”.
-
From the highest impact features we selected those that can be changed without breaking the executable file. We assumed that the contestants’ models should act similarly to our boosting model, for they depended on the same features.
During our model research, we found that the header, import table, directory table features are sometimes more important than the file sections data. So if you take a clean file, remove all sections and replace them with sections from the malware file, three out of six models will still consider it “clean”. We also found that one of the models used heuristics to cut off the last sections. If malware sections were added to the end of a clean file, the model’s verdict would be “clean”, but if inserted before the clean ones, the verdict would change to “malware”. Finally, we found the features helped to reliably bypass the four models mentioned. And for the other two, we found no consistent method to generate adversarial files (even not-working ones).
To completely change the section features with only minor file modification, we discovered this interesting shortcut. To calculate the feature vector, the creators of the Ember dataset used the FeatureHasher class from the sklearn.feature_extraction library. This class turns sequences of pairs (feature name, feature value) into an array of fixed length. First, it defines the position and sign (the sign will be important further on) by the hash of the feature name. Then FeatureHasher adds or subtracts (according to the sign) the corresponding feature value from the array position. The name of the section is used as the key for such hashing, and the value is determined by its size and entropy. Thus, for any given section you can add to the file another one with a specially constructed name, so the features of the new one will fall into the same cell of the hash table — but with opposite signs. Taking this idea further, you could zero out all the values in the hash table or construct any other values by adding a section of desired name and size to the end.
About the quality of the attacked models
We tried feeding various legitimate applications to the contestants’ models, such as Notepad, Paint, 7Zip, Putty, etc., including many Windows system executables. To our surprise, the models would very often recognize them as malicious. For example, the SECRET model, which took first place in the defensive part of the contest, detected most of the clean files we fed to it. Other models, too, kept detecting clean applications.
It might be incorrectly assumed that to win the competition the best protection strategy would be to recognize all files as malicious, except those that are “clean” in the training dataset. In reality such models don’t work. We think this is because the hidden test dataset is not representative enough to assess the quality of the good models. We further believe that the same Ember dataset was likely used by both the contestants and the organizers, so the models overfitted it. In the next iterations of the contest we would suggest expanding the test dataset for the defensive part of the contest with more clean files.
Final algorithm
As a result of our analysis, the following final algorithm was built for how to modify the target malicious files:
- Take a clean file not detected by any competing model. In this case, we selected the system file setupcl.exe (remember that non-system clean files were often detected by some models).
- Partially replace the malicious file’s header to make it look like that of a clean file (but the file itself should remain functional at the same time).
- Using the described section hash trick, zero out the “malware” section features, then add sections from the relevant clean file to the end of the file to add those “clean” features.
- Make changes to the directory table, so it looks more like a clean file’s table. This operation is the riskiest one, since the directory table contains the addresses and virtual sizes, the modification of which can make the file inoperable.
- Replace the static imports with dynamic ones (as a result, the import table turns empty, making it possible to fool models).
After these modifications (without checking the file behavior in the sandbox) we already had ~180 competition points — enough for second place. However, as you will learn later, we did not manage to modify all the files correctly.
Results
Some modification operations are quite risky in terms of maintaining correct file behavior (especially those with headers, directory tables and imports). Unfortunately, there were technical issues on the contest testing system side, so we had to test the modified files locally. Our test system had some differences, as a result, some of the modified files failed to pass the contest sandbox. As a result, we scored little and took only 6th place overall.
Conclusion
As anti-phishing experts, we were able to deduce, at least in general, how the models worked by observing their outputs and create an obfuscation scheme to fool them. This shows how hard the task of detecting phishing pages actually is, and why real-life production systems do not rely on HTML code alone to block them.
For us as malware experts, it was interesting to dive into some details of the structure of PE files and come up with our own ways to deceive anti-malware models. This experience will help us to improve our own models, making them less vulnerable to adversarial attacks. Also, it is worth mentioning that despite the number of sophisticated academic ML-adversarial techniques nowadays, the simple heuristic approach of modifying malicious objects was the winning tactic in the contest. We tried some of the adversarial ML techniques, but straightforward attacks requiring no knowledge of the model architecture or training dataset were still effective in many cases.
Overall, it was an exciting competition, and we want to thank the organizers for the opportunity to participate and hope to see MLSEC develop further, both technically and ideologically.
Table of Contents
- MLSEC.IO Phishing Track
- What we did
- Littering the page with invisible text
- Obfuscation via byte shift
- Obfuscation via byte integer encoding
- Less tags, more text
- Back to base (64)
- MLSEC.IO Anti-Malware Track
- Dataset
- First Experiments
- What features are important for the contest models?
- About the quality of the attacked models
- Final algorithm
- Results
- Conclusion
From the same authors





In the same category















How we took part in MLSEC and (almost) won