

Authors
What is an information security incident and how to respond to it?
Despite there being no revolutionary changes to the cyberthreat landscape in the last few years, the growing informatization of business processes provides cybercriminals with numerous opportunities for attacks. They are focusing on targeted attacks and learning to use their victims’ vulnerabilities more effectively while remaining under the radar. As a result, businesses are feeling the effects of next-gen threats without the appearance of new malware types.
Unfortunately, corporate information security services often turn out to be unprepared: their employees underestimate the speed, secrecy and efficiency of modern cyberattacks and do not recognize how ineffective the old approaches to security are. Even with traditional prevention tools such as anti-malware products, IDS/IPS and security scanners combined with detection solutions like SIEM and anti-APT, this costly complex may not be used to its full potential. And if there is no clear understanding of what sort of incident it is, an attack cannot be repelled.
More detailed information on the stages involved in organizing a cyberattack and responding to incidents can be found in the full version of this guide or obtained within the framework of Kaspersky Lab’s educational program. Here we will only focus on the main points.
Planning an attack
First of all, it should be noted that by targeted attacks we are referring to serious operations prepared by qualified cybercriminals. Cyber hooliganism such as defacing the homepage of a site carried out to attract attention or demonstrate capabilities, are not considered here. As a rule, successful activities of this kind means a company has no information security service to speak of, even if one exists on paper.
The basic principles of any targeted attack include thorough preparation and a stage-by-stage strategy. Here we will investigate the sequence of stages (known as the kill chain), using as an example an attack on a bank to steal money from ATMs.
1. Reconnaissance
At this stage, publicly available information about the bank and its data assets is collected. In particular, the attacker tries to determine the company’s organizational structure, tech stack, the information security measures as well as options for carrying out social engineering on its employees. The last point may include collecting information on forums and social networking sites, especially those of a professional nature.
2. Weaponization
Once the data is collected, cybercriminals choose the method of attack and select appropriate tools. They may use new or already existing malware that allows them to exploit detected security vulnerabilities. The malware delivery method is also selected at this stage.
3. Delivery
To deliver the necessary malware, email attachments, malicious and phishing links, watering hole attacks (infection of sites visited by employees of the targeted organization) or infected USB devices are used. In our example, the cybercriminals resorted to spear phishing, sending emails to specific bank employees on behalf of a financial regulator – the Central Bank of the Russian Federation (Bank of Russia). The email contained a PDF document that exploited a vulnerability in Adobe Reader.

4. Exploitation
In the event of a successful delivery, for example, an employee opening the attachment, the exploit uses the vulnerability to download the payload. As a rule, it consists of the tools necessary to carry out the subsequent stages of the attack. In our example, it was a Trojan downloader that, once installed, downloaded a bot from the attacker’s server the next time the computer was switched on.
If delivery fails, cybercriminals usually do not just give up; they take a step (or several steps) back in order to change the attack vector or malware used.
5. Installation
Malicious software infects the computer so that it cannot be detected or removed after a reboot or the installation of an update. For example, the above Trojan downloader registers itself in Windows startup and adds a bot there. When the infected PC is started next time, the Trojan checks the system for the bot and, if necessary, reloads it.
The bot, in turn, is constantly present in the computer’s memory. In order to avoid user suspicion, it is masked under a familiar system application, for example, lsass.exe (Local Security Authentication Server).

6. Command and control
At this stage, the malware waits for commands from the attackers. The most common way to receive commands is to connect the C&C server that belongs to the fraudsters. This is what the bot in our example did: when it first addressed the C&C server, it received a command to carry out further proliferation (lateral movement) and began to connect to other computers within the corporate network.
If infected computers do not have direct access to the Internet and cannot connect directly to the C&C server, the attacker can send other software to the infected machine, deploy a proxy server in the organization’s network, or infect physical media to overcome the ‘air gap’.
7. Actions on objective
Now, the cybercriminals can work with the data on a compromised computer: copying, modifying or deleting it. If the necessary information is not found, the attackers may try to infect other machines in order to increase the amount of available information or to obtain additional information that allows them to reach their primary goal.
The bot in our example infected other PCs in search of a machine from which it could log on as an administrator. Once such a machine was found, the bot turned to the C&C server to download the Mimikatz program and the Ammyy Admin remote administration tools.
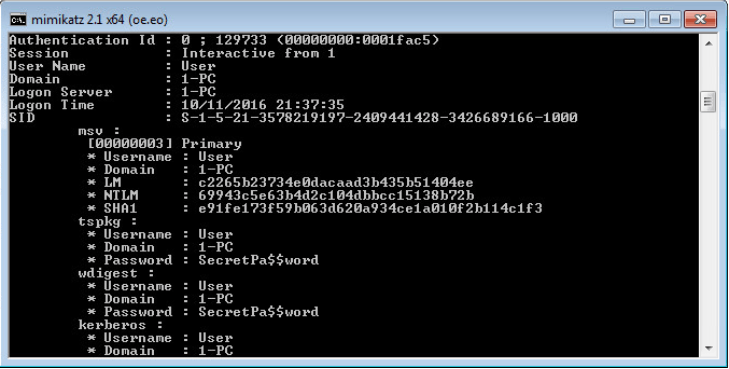
Example of Mimikatz execution. All the logins and passwords are entered in clear view, including the Active Directory user passwords.
If successful, the bot can connect to the ATM Gateway and launch attacks on ATMs: for example, it can implement a program in an ATM that will dispense cash when a special plastic card is detected.
The final stage of the attack is removing and hiding any traces of the malware in the infected systems, though these activities are not usually included in the kill chain.
The effectiveness of incident investigation and the extent of material and reputational damage to the affected organization directly depend on the stage at which the attack is detected.

If the attack is detected at the ‘Actions on objective’ stage (late detection), it means the information security service was unable to withstand the attack. In this case, the affected company should reconsider its approach to information security.
My network is my castle
We have analyzed the stages of a targeted attack from the point of view of cybercriminals; now let’s look at it from the point of view of the affected company’s information security staff. The basic principles behind the work of both sides are essentially the same: careful preparation and a step-by-step strategy. But the actions and tools of the information security specialists are fundamentally different because they have very different objectives, namely:
- Mitigate the damage caused by an attack;
- Restore the initial state of the information system as quickly as possible;
- Develop instructions to prevent similar incidents in future.
These objectives are achieved in two main stages – incident investigation and system restoration. Investigation must determine:
- Initial attack vector;
- Malware, exploits and other tools used by the attackers;
- Target of the attack (affected networks, systems and data);
- Extent of damage (including reputational damage) to the organization;
- Stage of attack (whether it is completed and goals are achieved);
- Time frames (time the attack started and ended, when it was detected in the system and response time of the information security service).
Once the investigation is completed, it is necessary to develop and implement a system recovery plan, using the information obtained during investigation.
Let’s return to the step-by-step strategy. Overall, the incident response protection strategy looks like this:

Incident response stages
As with the stages of the targeted attack, we will analyze in more detail each stage involved in combating an attack.
1. Preparation
Preparation includes developing processes and policies and selecting tools. First of all, it means the creation of a multi-level security system that can withstand intruders using several attack vectors. The levels of protection can be divided into two groups.
The first includes the installation of tools designed to prevent attacks (Prevention):
- security solutions for workstations;
- intrusion detection and intrusion prevention systems (IDS/IPS);
- firewall to protect the Internet gateway;
- proxy server to control Internet access.
The second group consists of solutions designed to detect threats (Detection):
- SIEM system with integrated threat reporting component that monitors events occurring in the information system;
- Anti-APT system that compares data on detected threats delivered by various security mechanisms;
- Honeypot – a special fake object for cyberattacks that is isolated and closely monitored by the information security service;
- EDR-systems (tools for detecting and responding to threats on endpoints) that raise awareness of events occurring on endpoints and enable automatic containment and elimination of threats.
The organization we chose as an example was ready for unexpected attacks. The ATMs were separated from the main network of the bank, with access to the subnet limited to authorized users.

Network of the attacked organization
The SIEM system was used to monitor and analyze events occurring on the network. It collected:
- information about network connections to the proxy server that was used by all employees to access the Internet;
- integrated threat data feeds provided by Kaspersky Lab specialists;
- notifications of emails that passed through the Postfix mail server, including information about headers, DKIM signatures, etc.;
SIEM also received information about security solution activation on any workstation in the corporate IT infrastructure.
Another important preparation element is penetration testing to predict the possible vector of a cyberattack. Penetration of the corporate network can be simulated by both the company’s IT specialists and third-party organizations. The latter option is more expensive, though preferable: organizations that specialize in pen tests have extensive experience and are better informed about the current threat vectors.
The last – but by no means least – important element is educating the organization’s employees. This includes internal cybersecurity training for all employees: they should be aware of the corporate security policies and know what to do in the event of a cyberattack. It also includes targeted training for specialists responsible for the company’s information security, as well as the accumulation of information about security incidents inside and outside the company. This information may come from different sources such as internal company reports or third-party organizations that specialize in analyzing cyberthreats, for example, Kaspersky Threat Intelligence Portal.
2. Identification
At this stage, it is necessary to determine whether it is actually an incident or not. Only then can the alarm be raised and colleagues warned. In order to identify an incident, so-called triggers are used – events that indicate a cyberattack. These include attempts by a workstation to connect to a known malicious C&C server, errors or failures in security software performance, unexpected changes to user rights, unknown programs on the network, and much more.
Information about these events can come from a variety of sources. Here we will consider two key types of triggers:
- Triggers generated by EPP management systems. When a security solution on one of the workstations detects a threat, it generates an event and sends it to the management system. However, not all events are triggers: for example, an event that indicates the detection of a malicious program can be followed by an event about its neutralization. In this case, investigation is not necessary, except when the situation occurs regularly on the same machine or with the same user.
- Incident triggers generated by SIEM systems. SIEM systems can accumulate data from a huge number of security controls, including proxy servers and firewalls. Triggers are only considered to be those events that are created based on comparing incoming data and threat reports.
To identify an incident, the information available to the information security service is compared with a list of known indicators of compromise (IOC). Public reports, threat data feeds, static and dynamic sample analysis tools, etc. can be used for this purpose.
Static analysis is performed without launching the test sample and includes collecting various indicators, such as strings containing a URL or an email address, etc. Dynamic analysis involves executing the program under investigation in a protected environment (sandbox) or on an isolated machine in order to identify the sample’s behavior and collect indicators of compromise.

Cycle of IOC detection
As seen from the picture above, collecting IOCs is a cyclic process. Based on the initial information from the SIEM system, identification scenarios are generated, which leads to the identification of new indicators of compromise.
Here is an example of how threat data feeds can be used to identify a spear-phishing attack – in our case, emails with an attached PDF document that exploits an Adobe Reader vulnerability.
- SIEM will detect the IP address of the server that sent the email using IP Reputation Data Feed.
- SIEM will detect the request to load the bot using Malicious URL Data Feed.
- SIEM will detect a request to the C&C server using Botnet C&C URL Data Feed.
- Mimikatz will be detected and removed by a security solution for workstations; information about the detection will go to SIEM.
Thus, at an early stage, an attack can be detected in four different ways. It also means the company will suffer minimal damage.
3. Containment
Suppose that, due to a heavy workload, the information security service couldn’t respond to the first alarms, and by the time there was a response, the attack had reached the sixth stage, i.e., malware had successfully penetrated a computer on the corporate network and tried to contact the C&C server, and the SIEM system had received notice of the event.
In this case, the information security specialists should identify all compromised computers and change the security rules to prevent the infection from spreading over the network. In addition, they should reconfigure the information system so that it can ensure the company’s continuous operation without the infected machines. Let’s consider each of these actions in more detail.
Isolation of compromised computers
All compromised computers should be identified, for example, by finding in SIEM all calls to the known C&C address – and then placed in an isolated network. In this case, the routing policy should be changed to prevent communication between compromised machines and other computers on the corporate network, as well as the connection of compromised computers to the Internet.
It is also recommended to check the C&C address using a special service, for example, Threat Lookup. As a result, this provides not only the hashes of the bots that interacted with the C&C server but also the other addresses the bots contacted. After that it is worth repeating the search in SIEM across the extended list of indicators, since the same bot may have interacted with several C&C servers on different computers. All infected workstations that are identified must be isolated and examined.
In this case, the compromised computers should not be turned off, as this can complicate the investigation. Specifically, some types of malicious program only use the computer’s RAM and do not create files on the hard disk. Other malware can remove an IOC once the system receives a turn-off signal.
Also, it is not recommended to disconnect (primarily physically) the local network connections of the affected PC. Some types of malware monitor the connection status, and if the connection is not available for a certain period of time, malware can begin to remove traces of its presence on the computer, destroying any IOCs. At the same time, it makes sense to limit the access of infected machines to the internal and external networks (for example, by blocking the transfer of packets using iptables).
For more information on what to do if the search by a C&C address does not provide the expected results, or on how to identify malware, read the full version of this guide.
Creation of memory dumps and hard disk dumps
By analyzing memory dumps and hard disk dumps of compromised computers, you can get samples of malware and IOCs related to the attack. The study of these samples allows you to understand how to deal with the infection and identify the vector of the threat in order to prevent a repeat infection using a similar scenario. Dumps can be collected with the help of special software, for example, Forensic Toolkit.
Maintaining system performance
After the compromised computers are isolated, measures should be taken to maintain operation of the information system. For example, if several servers were compromised on the corporate network, changes should be made to the routing policy to redirect the workload from compromised servers to other servers.
4. Eradication
The goal of this stage is to restore the compromised information system to the state it was in before the attack. This includes removing malware and all artifacts that may have been left on the infected computers, as well as restoring the initial configuration of the information system.
There are two possible strategies to do this: full reinstallation of the compromised device’s OS or simply removing any malicious software. The first option is suitable for organizations that use a standard set of software for workstations. In this case, you can restore the operation of the latter using the system image. Mobile phones and other devices can be reset to the factory settings.
In the second case, artifacts created by malware can be detected using specialized tools and utilities. More details about this are available in the full version of our guide.
5. Recovery
At this stage, those computers that were previously compromised are reconnected to the network. The information security specialists continue to monitor the status of these machines to ensure the threat has been eliminated completely.
6. Lessons learned
Once the investigation has been completed, the information security service must submit a report with answers to the following questions:
- When was the incident identified and who identified it?
- What was the scale of the incident? Which objects were affected by the incident?
- How were the Containment, Eradication, and Recovery stages executed?
- At what stages of incident response do the actions of the information security specialists need to be corrected?
Based on this report and the information obtained during the investigation, it is necessary to develop measures to prevent similar incidents in the future. These can include changes to the security policies and configuration of corporate resources, training on information security for employees, etc. The indicators of compromise obtained during the incident response process may be used to detect other attacks of this kind in the future.
In order of priority
Troubles come in threes, or so the saying goes, and it can be the case that information security specialists have to respond to several incidents simultaneously. In this situation, it is very important to correctly set priorities and focus on the main threats as soon as possible – this will minimize the potential damage of an attack.
We recommend determining the severity of an incident, based on the following factors:
- Network segment where the compromised PC is located;
- Value of data stored on the compromised computer;
- Type and number of other incidents that affected the same PC;
- Reliability of the indicator of compromise for the given incident.
It should be noted that the choice of server or network segment that should be saved first, and the choice of workstation that can be sacrificed, depends on the specifics of the organization.
If the events, originating from one of the sources, include an IOC published in a report on APT threats or there is evidence of interaction with a C&C server previously used in an APT attack, we recommend dealing with these incidents first. The tools and utilities described in the full version of our Incident Response Guide can help.
Conclusion
It is impossible in one article to cover the entire arsenal that modern cybercriminals have at their disposal, describe all existing attack vectors, or develop a step-by-step guide for information security specialists to help respond to every incident. Even a series of articles would probably not be sufficient, as modern APT attacks have become extremely sophisticated and diverse. However, we hope that our recommendations about identifying incidents and responding to them will help information security specialists create a solid foundation for reliable multi-level business protection.
Table of Contents
- Planning an attack
- 1. Reconnaissance
- 2. Weaponization
- 3. Delivery
- 4. Exploitation
- 5. Installation
- 6. Command and control
- 7. Actions on objective
- My network is my castle
- 1. Preparation
- 2. Identification
- 3. Containment
- Isolation of compromised computers
- Creation of memory dumps and hard disk dumps
- Maintaining system performance
- 4. Eradication
- 5. Recovery
- 6. Lessons learned
- In order of priority
- Conclusion
From the same authors





In the same category
















Neutralization reaction