

Authors
The Global Research & Analysis Team here at Kaspersky has a tradition of meeting up once a month and sharing cutting-edge research, interesting techniques and useful tools. We recently took the unprecedented decision to make our internal meetings public for a few months and present them as a series of talks called ‘GReAT Ideas. Powered by SAS’. In the second edition that takes place on July 22, 2020, I’ll be talking about awesome IDA Pro plugins that I regularly use. This article is a sneak peek into what I’ll be discussing.
Highlighting control-flow transfer instructions
When you are reverse-engineering a binary it’s very important to follow control-flow transfer instructions and especially those instructions that are used to transfer the control flow to other procedures. For x86/64 architectures this is done by the CALL instruction. If you’re an experienced reverse engineer, you can usually get a general idea of what a function does just by taking a quick look at the function assembly (especially true when the function is relatively small). When it comes to understanding what a function does, the first thing you’re most likely to do is check how many CALL instructions it has and what other functions they execute. If a function just performs calculations, stores some values in memory, and you don’t really care about such details, then you can skip this function and continue reverse-engineering. It’s quite different when a function executes other functions; you might want to understand what these functions do first to get the bigger picture.
All development environments for writing code support syntax highlighting because it greatly assists in software coding. However, syntax highlighting can also greatly assist in software reversing. Let’s take a quick look at syntax highlight capabilities provided by IDA Pro and other tools for reverse engineering.
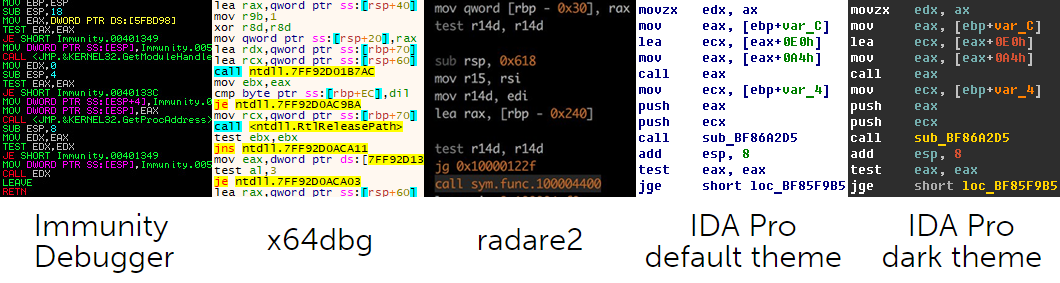
As you can see, Immunity Debugger, x64dbg and radare2 all highlight control-flow transfer instructions, but not IDA Pro. The default IDA Pro theme just looks plain. However, it’s possible to brighten things up a bit if you go to “Options -> Colors…”. In the IDA Colors window you can configure different colors for instruction mnemonics, registers, addresses, constants and variables. It makes IDA Pro output much more pleasant on the eye, but it doesn’t solve the problem completely because all instruction mnemonics will have the same color and if you rely on address highlighting, it’s not going to work with indirect function calls. Why doesn’t IDA Pro have an option to highlight CALL instructions? To this day, this omission bothers me. And it seems it’s not just me because there have been a number of scripts and plugins aimed at the same issue – fluorescence.py and highlight_calls.py – to name just a couple. These scripts use API functions set_color()/set_item_color() to set background color behind an instruction. And while it definitely does the job, the final result is not as good as it could be if it was possible to change the color of some particular instruction mnemonics.
At some point, I decided to check if there was a way to change the color of some particular instructions with a more advanced plugin and dived into IDA Pro SDK header files. I found what I was looking for inside the lines.hpp header file, which reveals the internal format used by IDA Pro to display disassembled text. It turns out that the API functions generate_disassembly() and generate_disasm_line() output disassembled text lines along with special escape sequences that are used to implement syntax highlighting. If you use idc.generate_disasm_line(ea, flags) with IDAPython, then these color escape sequences will be removed from the output, but you can still take a look at raw disassembled text lines if you use ida_lines.generate_disasm_line(ea, flags). The format for color escape sequences is fairly simple and a typical color sequence looks like this: #COLOR_ON #COLOR_xxx text #COLOR_OFF #COLOR_xxx. #COLOR_ON is equal to ‘\x01’ and the #COLOR_xxx value for instruction mnemonic is defined as COLOR_INSN and equal to ‘\x05’. As a result, the disassembly text line for the CALL instruction will always begin with ‘\x01\x05call\x02\x05’. IDA Pro SDK also provides the function hook_to_notification_point() that can be used to install callbacks for different events, and those events include the UI notification ui_gen_idanode_text which can be used to provide custom text for an IDA graph node. So, the plan is as follows: we make a callback for ui_gen_idanode_text notification, check if the disassembled text line at the current address starts with ‘\x01\x05call\x02\x05’, and if so, we replace COLOR_INSN with the ID of some another color. After writing the necessary code and testing it, I was happy to see that my plan worked out pretty well!
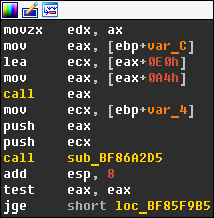
I achieved exactly what I wanted, but I still wasn’t completely satisfied. The problem with this approach is that it is only going to work with x86/64, but what about ARM, MIPS, etc.? I needed a CPU-agnostic solution. Thankfully, it was quite easy to implement. Each processor module has a special exported structure (processor_t) called LPH. This structure has an instruc field that is a pointer to an array of processor instructions. Each instruction in this table is represented by an instruction mnemonic and a combination of its features. These features include what operand it modifies (CF_CHGX), which operand it uses (CF_USEX), whether it halts execution (CF_STOP), makes a jump to another location (CF_JUMP) or calls another procedure (CF_CALL). It means that at plugin start we can parse the list of instructions from the loaded processor module, find all the instructions that have the CF_CALL feature and use them later in comparison. You can see the results below.
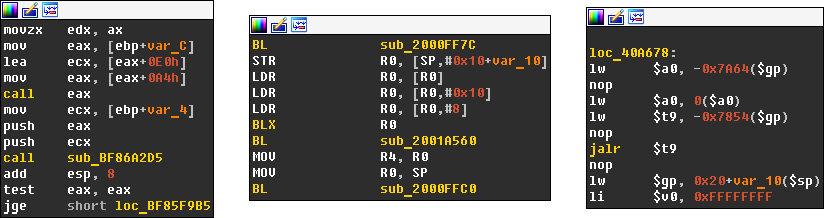
As long as the processor module fills the instruc table properly, my plugin should work fine. So far, I’ve only encountered problems with PowerPC, because in this particular case all necessary instructions like “bl” and “bctrl” are missing in the instruc table. But it’s still possible to create workarounds for them.
Identification of known functions
Identification of known functions is a huge reverse engineering problem. The two scenarios below are likely to be familiar to you:
- You are reverse-engineering a binary without debug symbols that is statically linked with a known library and you want to automatically rename all functions from this library in your IDA Pro database file.
- You’ve spent some time reverse engineering a binary without debug symbols, but a new version of the binary appears and you want to port all your renamed functions to a new IDA Pro database file.
To address the first issue, Hex-Rays, the company behind IDA Pro, has come up with a technology for storing and applying signatures for library function identification. This technology is called FLIRT. It makes it possible to use a special utility to preprocesses *.obj and *.lib files, produce the file *.pat with the function patterns and other necessary data and then convert it into the signature file *.sig. In the end you get a signature file for a specific library that you can put into the “sig\<arch>” folder inside the IDA Pro directory and apply it to your IDA Pro database from the “View -> Open subviews -> Signatures” window. If the functions in a library match those functions present in your IDA Pro database byte to byte, then they will be recognized and renamed properly.
While the previously described method partially solves the first issue, it doesn’t help at all with the second issue. Officially, FLIRT only provides a way to create signature files for libraries, so it can’t be used to transfer knowledge from one IDA Pro database to another. After many years, this problem was finally addressed in IDA Pro 7.2. This release introduced a new technology called Lumina server. It can be used to push and retrieve metadata about functions (names, comments, etc.) present in a database. However, it doesn’t really help when you want to transfer this info from one database to another without sharing this info with the rest of the world. That’s because currently only a public Lumina server is available. It means the only way to do this is to use plugins. Thankfully, these kinds of plugins have been around for ages. IDA2PAT and IDB2SIG can be used to generate a FLIRT file from an existing IDA Pro database and then apply it to a new database just as if it was a regular signature file for a library. They are fairly easy to use and if a function is not identified in the new database, you can see straightaway that it was changed. The original IDA2PAT and IDB2SIG plugins are not maintained, so you might want to use a fork with IDA Pro 7.* support or modern IDAPython port idb2pat.py.
As was previously mentioned, the downside of FLIRT technology is that it only works when the signature closely matches the bytes of the function body. This could be a problem when, for example, you only have the source code of a library and when you try to compile it the result doesn’t really match your analyzed binary. In such cases, binary diffing comes in handy. The great feature of BinDiff and Diaphora plugins is that they can not only be used to compare functions between different binaries but also port function names and comments. You might also want to give Karta a try. It’s been developed especially for identifying library functions in a binary directly from the source code. You can read more about how it works in here.
YARA + IDA Pro = ❤
YARA is the Swiss Army knife of pattern matching. It’s probably the most beloved tool of malware researchers – and still massively underrated by everyone else. Pattern matching can be really useful in reverse engineering and YARA is the tool to use. Here are just some of the uses: look for important constants, magic values, GUIDs in your IDA Pro database and print a message, rename an address or leave a comment when a match is found. The key here is to know what you can look for with YARA and how it can improve your workflow. For example, the plugin findcrypt-yara uses YARA to find common cryptographic constants.
Below I demonstrate how you can use YARA within IDA Pro by yourself. Note that you need to install the yara-python package first.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import idaapi, idautils, idc import yara # rules can be compiled from a file path or as string rules = yara.compile(filepath=file_with_rules) # iterate all segments present in database for segment_start in idautils.Segments(): segment_size = get_segm_end(segment_start) - segment_start # read segment data data = get_bytes(segment_start, segment_size) # scan segment data with rules matches = rules.match(data=data) # iterate all matched data for m in matches: for s in m.strings: offset = s[0] name = s[1] # leave a comment with pattern name at matched offset in database set_cmt(get_item_head(segment_start+offset), name, 0) |
Let me know about your favorite IDA Pro plugins on Twitter and sign up for our upcoming ‘GReAT Ideas. Powered by SAS’ webinar to learn more about some other awesome plugins.
From the same authors





In the same category
















GReAT thoughts: Awesome IDA Pro plugins