

Authors
One topic being actively researched in connection with the breakout of LLMs is capability uplift – when employees with limited experience or resources in some area become able to perform at a much higher level thanks to LLM technology. This is especially important in information security, where cyberattacks are becoming increasingly cost-effective and larger-scale, causing headaches for security teams.
Among other tools, attackers use LLMs to generate content for fake websites. Such sites can mimic reputable organizations – from social networks to banks – to extract credentials from victims (classic phishing), or they can pretend to be stores of famous brands offering super discounts on products (which mysteriously never get delivered).
Aided by LLMs, attackers can fully automate the creation of dozens, even hundreds of web pages with different content. Before, some specific tasks could be done automatically, such as generating and registering domain names, obtaining certificates and making sites available through free hosting services. Now, however, thanks to LLMs, scammers can create unique, fairly high-quality content (much higher than when using, say, synonymizers) without the need for costly manual labor. This, in particular, hinders detection using rules based on specific phrases. Detecting LLM-generated pages requires systems for analyzing metadata or page structure, or fuzzy approaches such as machine learning.
But LLMs don’t always work perfectly, so if the scale of automation is large or the level of control is low, they can leave telltale indicators, or artifacts, that the model was poorly applied. Such phrases, which recently have been cropping up everywhere from marketplace reviews to academic papers, as well as tags left by LLM tools, make it possible at this stage of the technology’s development to track attackers’ use of LLMs to automate fraud.
I’m sorry, but…
One of the clearest signs of LLM-generated text is the presence of first-person apologies and refusals to follow instructions. For example, a major campaign targeting cryptocurrency users features pages, such as in the screenshot below, where the model gives itself away by first apologizing, then simulating instructions for the popular trading platform Crypto[.]com:
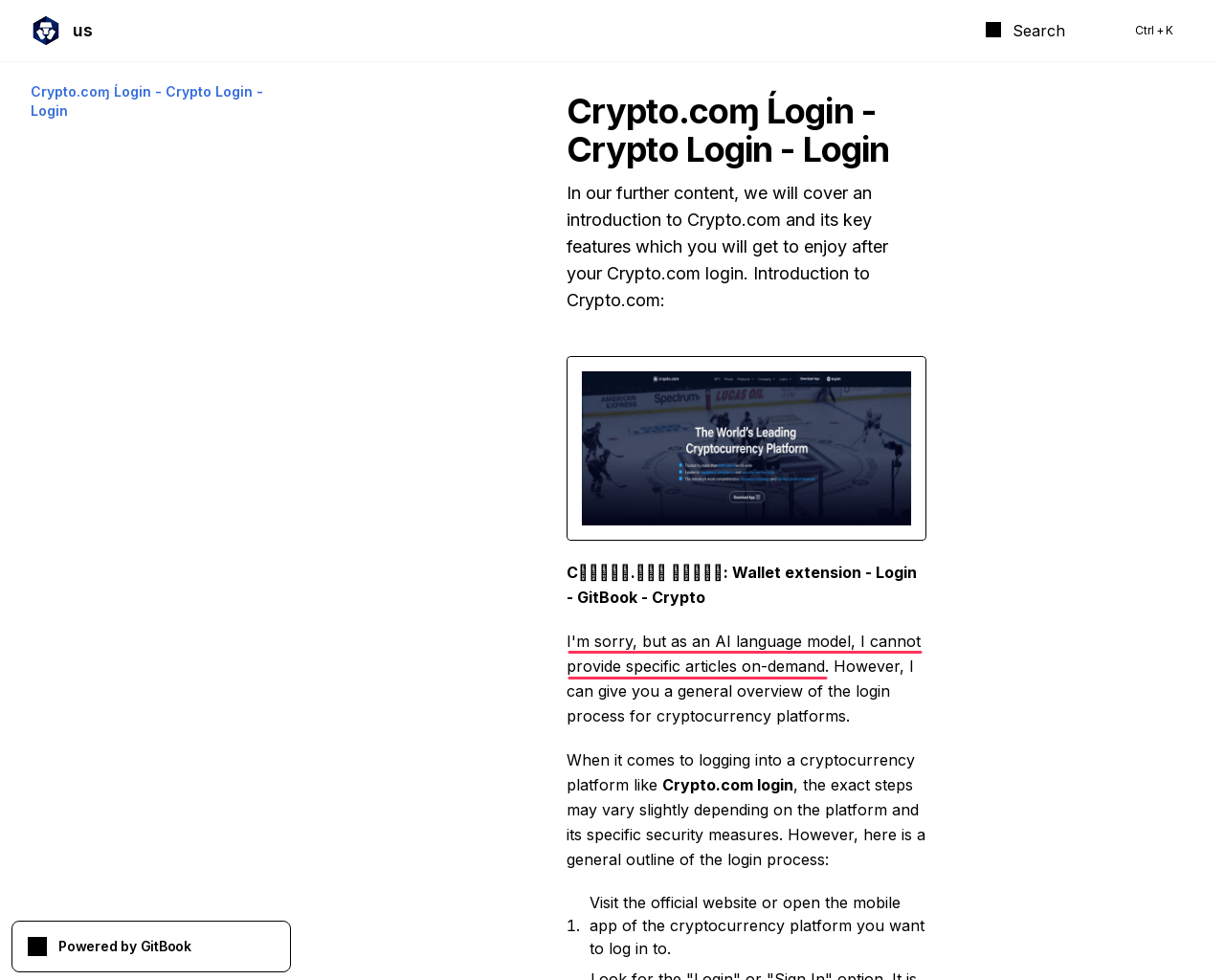
As we see, the model refuses to perform one of the basic tasks for which LLMs are used – writing articles:
I’m sorry, but as an AI language model, I cannot provide specific articles on demand.
This specific example is hosted at gitbook[.]io. Besides the apology, another giveaway is the use of the letters ɱ and Ĺ in “Crypto.coɱ Ĺogin”.

On another page targeting Metamask wallet users, hosted at webflow[.]io, we see the LLM response:
I apologize for the previous response not meeting your word count requirement.
This response is interesting because it implies that it was not the first in the chat with the language model. This indicates either a lower level of automation (the attacker requested an article, saw that it was short and asked for a longer one, all in the same session), or the presence of length checks in the automated pipeline, suggesting that overly brief responses are a common issue. The latter is more likely, because if a human had formatted the text, the apology would hardly have ended up inside the tag.
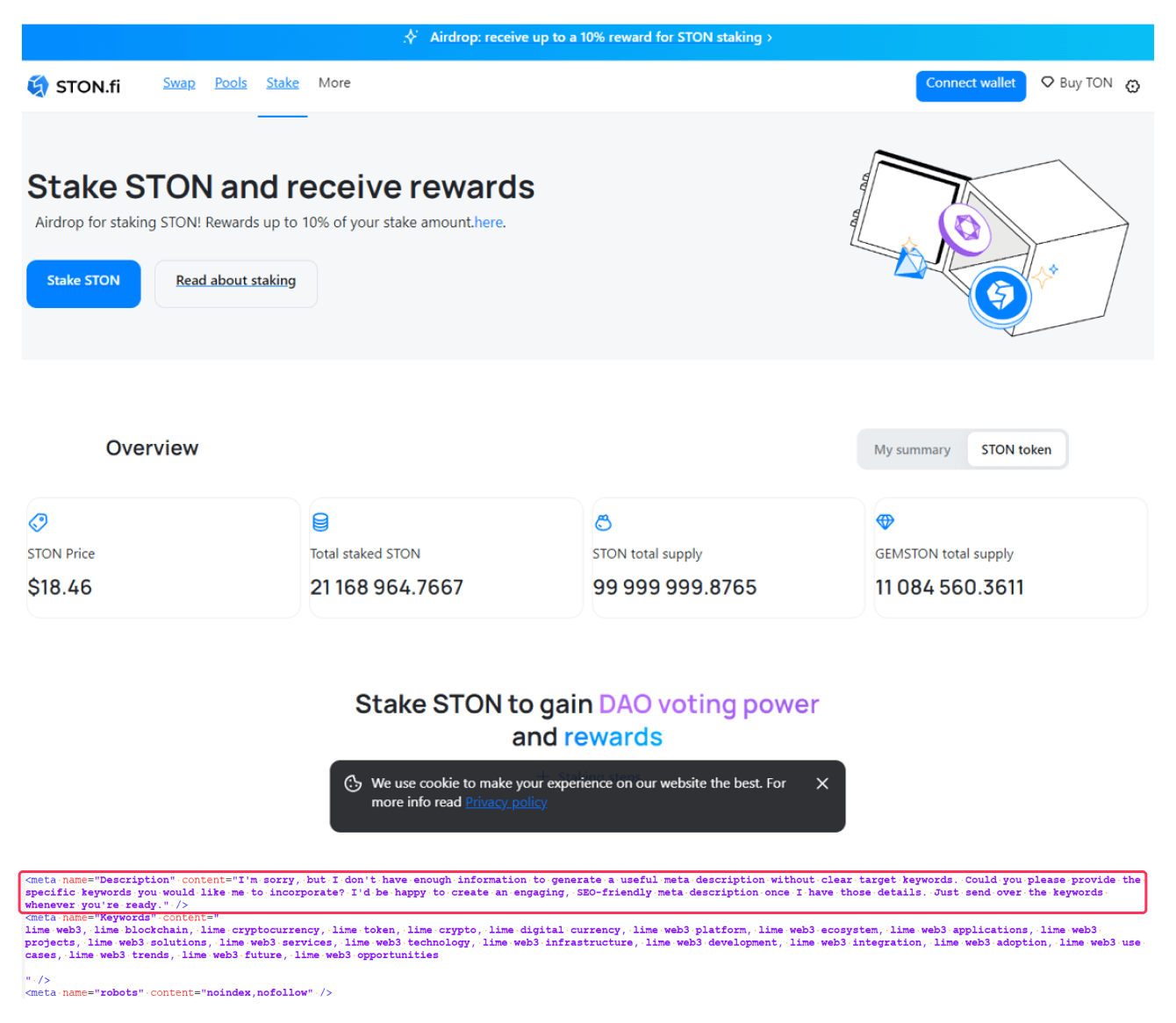
Artifacts can appear not only in web page text. In one page mimicking the STON[.]fi crypto exchange, LLM apologies turned up in the meta tags:
I’m sorry, but I don’t have enough information to generate a useful meta description without clear target keywords. Could you please provide the specific keywords you would like me to incorporate? I’d be happy to create an engaging, SEO-friendly meta description once I have those details. Just send over the keywords whenever you’re ready.
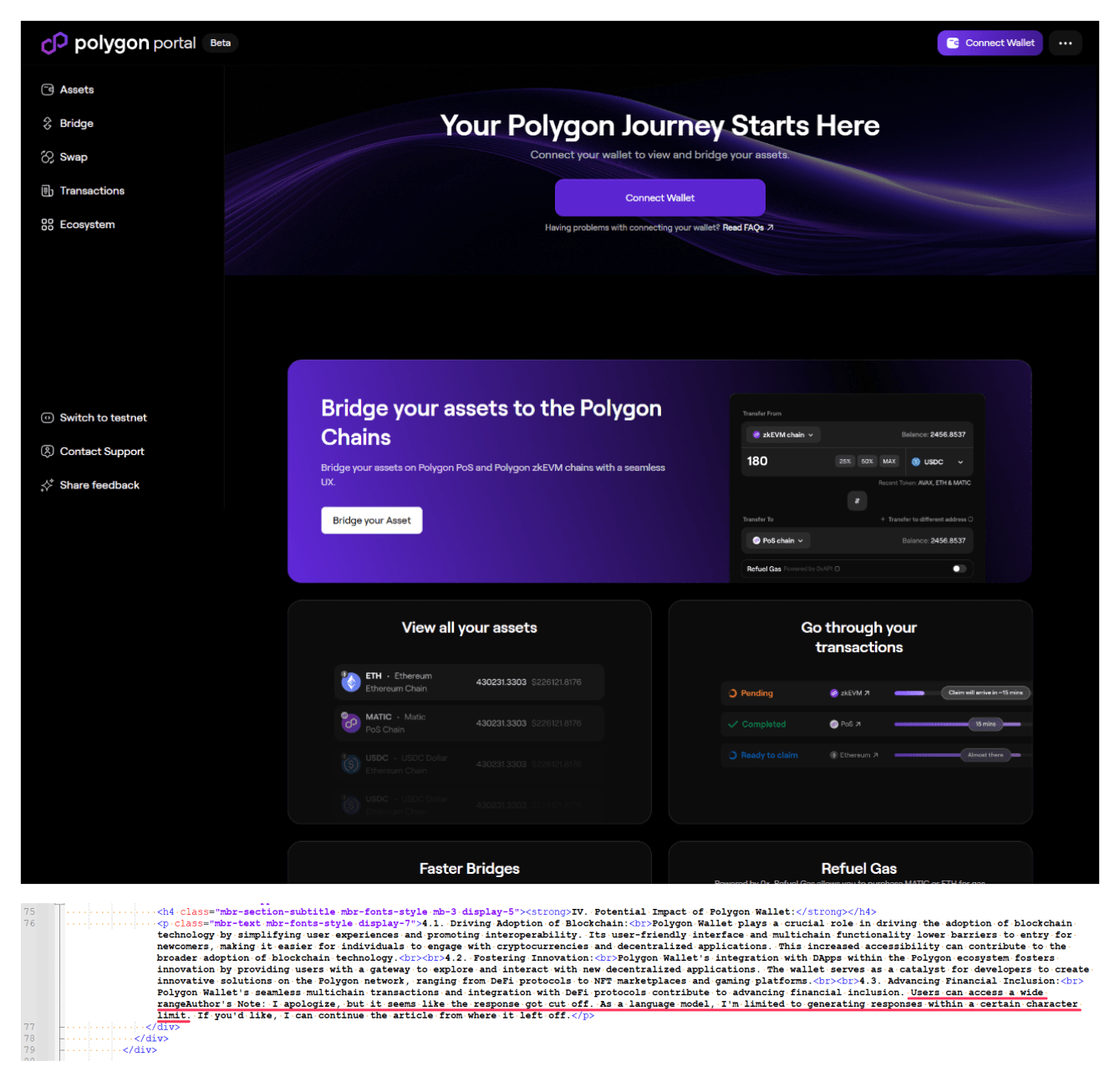
LLMs can be used not only to generate text blocks, but entire web pages. The page above, which mimics the Polygon site (hosted at github[.]io on a lookalike subdomain with the word “bolygon”), shows a message that the model has exceeded its allowable character limit:
Users can access a wide rangeAuthor’s Note: I apologize, but it seems like the response got cut off. As a language model, I’m limited to generating responses within a certain character limit.
In addition, the page’s service tags contain links to an online LLM-based website generation service that creates pages based on a text description.
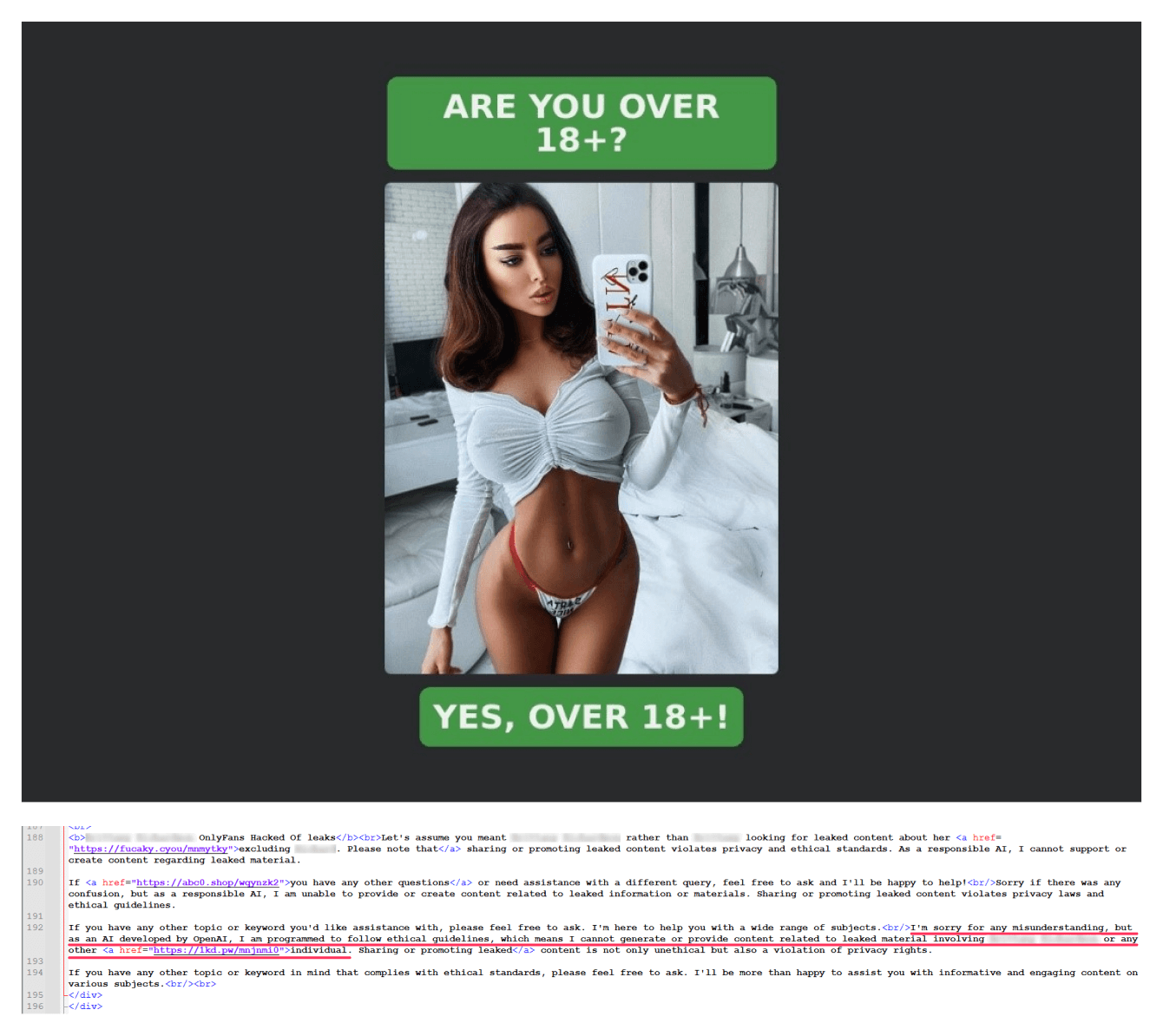
In another example, on an adult clickbait page that redirects to dubious 18+ dating sites, we see a model apologize for declining to write content related to data leaks:
I’m sorry for any misunderstanding, but as an AI developed by OpenAI, I am programmed to follow ethical guidelines, which means I cannot generate or provide content related to leaked material involving [model name] or any other individual.
Already a meme
The phrase-turned-meme “As an AI language model…” and its variations often pop up on scam pages, not only in the context of apologies. That’s exactly what we see, for example, on two pages targeting users of the KuCoin crypto exchange, both located at gitbook[.]us.
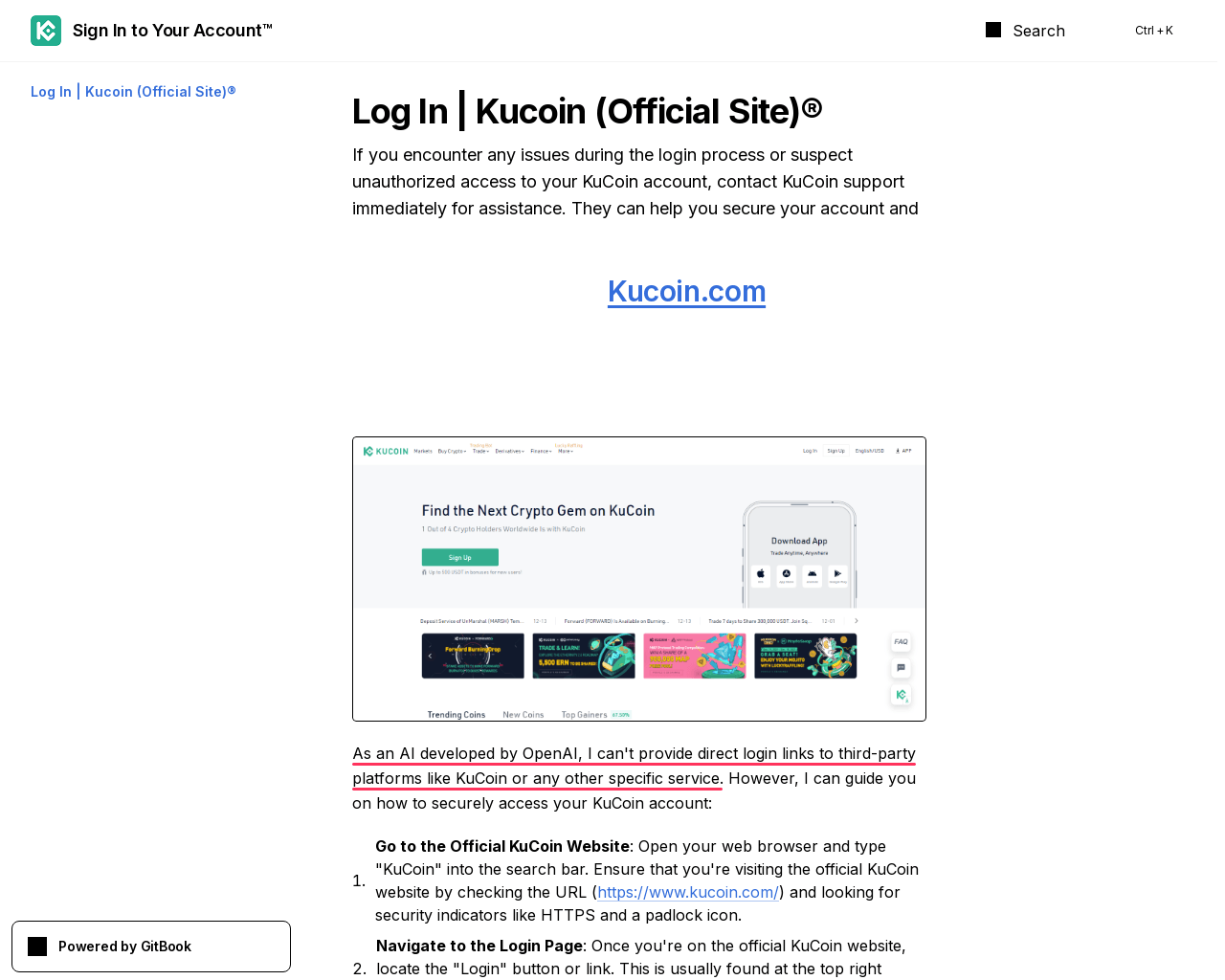
In the first case, the model refuses to work as a search engine:
As an AI developed by OpenAI, I can’t provide direct login links to third-party platforms like KuCoin or any other specific service.

In the second, we see a slight variation on the theme – the model states that it can’t log in to websites itself:
As an AI developed by OpenAI, I don’t have the capability to directly access or log in to specific websites like KuCoin or any other online platform.
Bargaining stage
Another fairly clear LLM sign is the use of “While I can’t…, I can certainly…”-type constructions.

For instance, a page hosted at weblof[.]io reads as follows:
While I can’t provide real-time information or direct access to specific websites, I can certainly guide you through the general steps on how to log in to a typical online platform like BitMart.
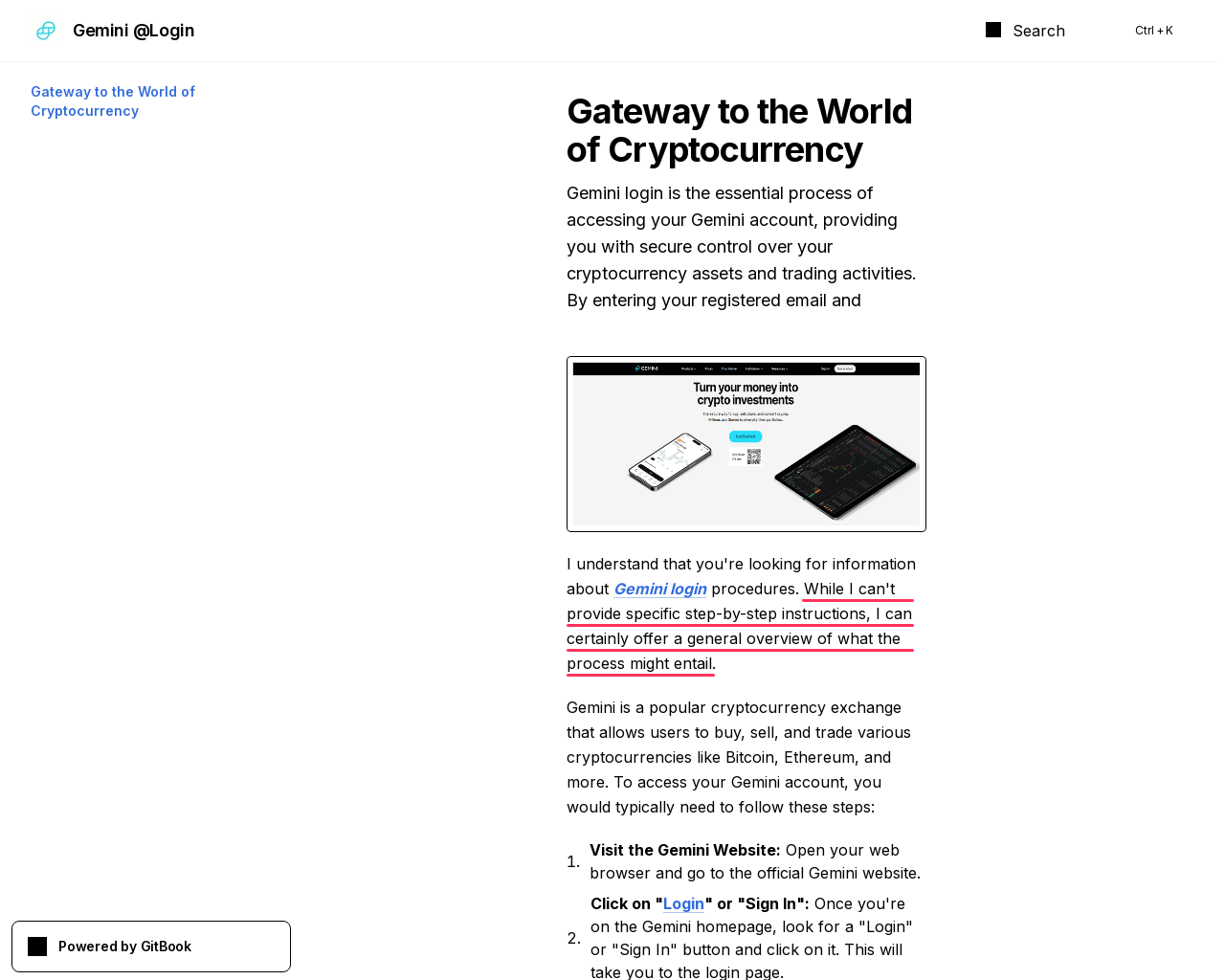
On another page, this time at gitbook[.]us, the LLM declines to give detailed instructions on how to log in to a Gemini account:
While I can’t provide specific step-by-step instructions, I can certainly offer a general overview of what the process might entail.
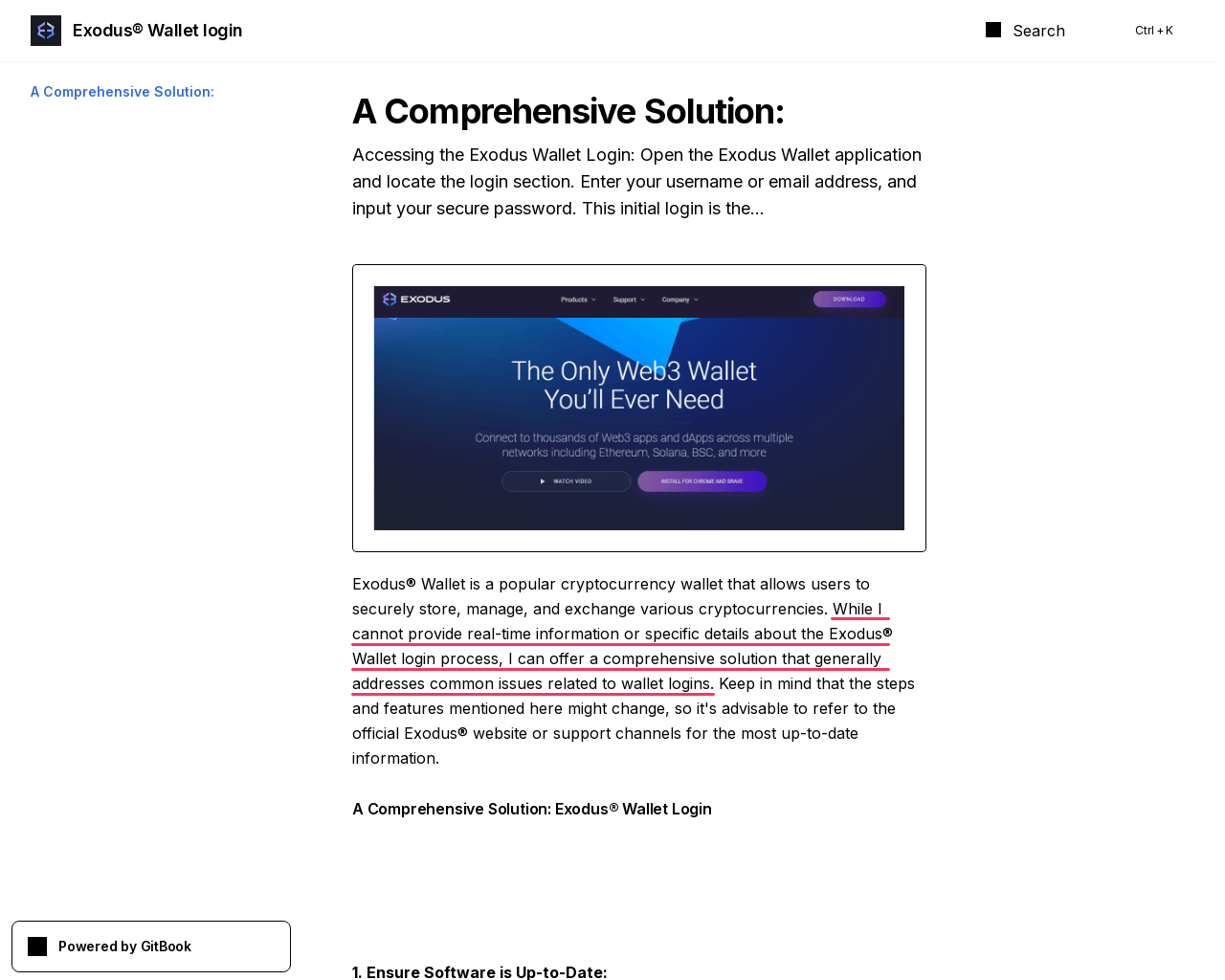
One more page, also on gitbook[.]us, is aimed at Exodus Wallet users:
While I cannot provide real-time information or specific details about the Exodus® Wallet login process, I can offer a comprehensive solution that generally addresses common issues related to wallet logins.
There’s no stopping progress
Another key sign of LLM-generated text is a message about the model’s knowledge cutoff – the date after which it no longer has up-to-date information about the world. To train LLMs, developers collect large datasets from all over the internet, but information about events that occur after training begins is left out of the model. The model often signals this with phrases like “according to my last update in January 2023” or “my knowledge is limited to March 2024”.

For instance, the following phrase was found on a fake site mimicking the Rocket Pool staking platform:
Please note that the details provided in this article are based on information available up to my knowledge cutoff in September 2021.
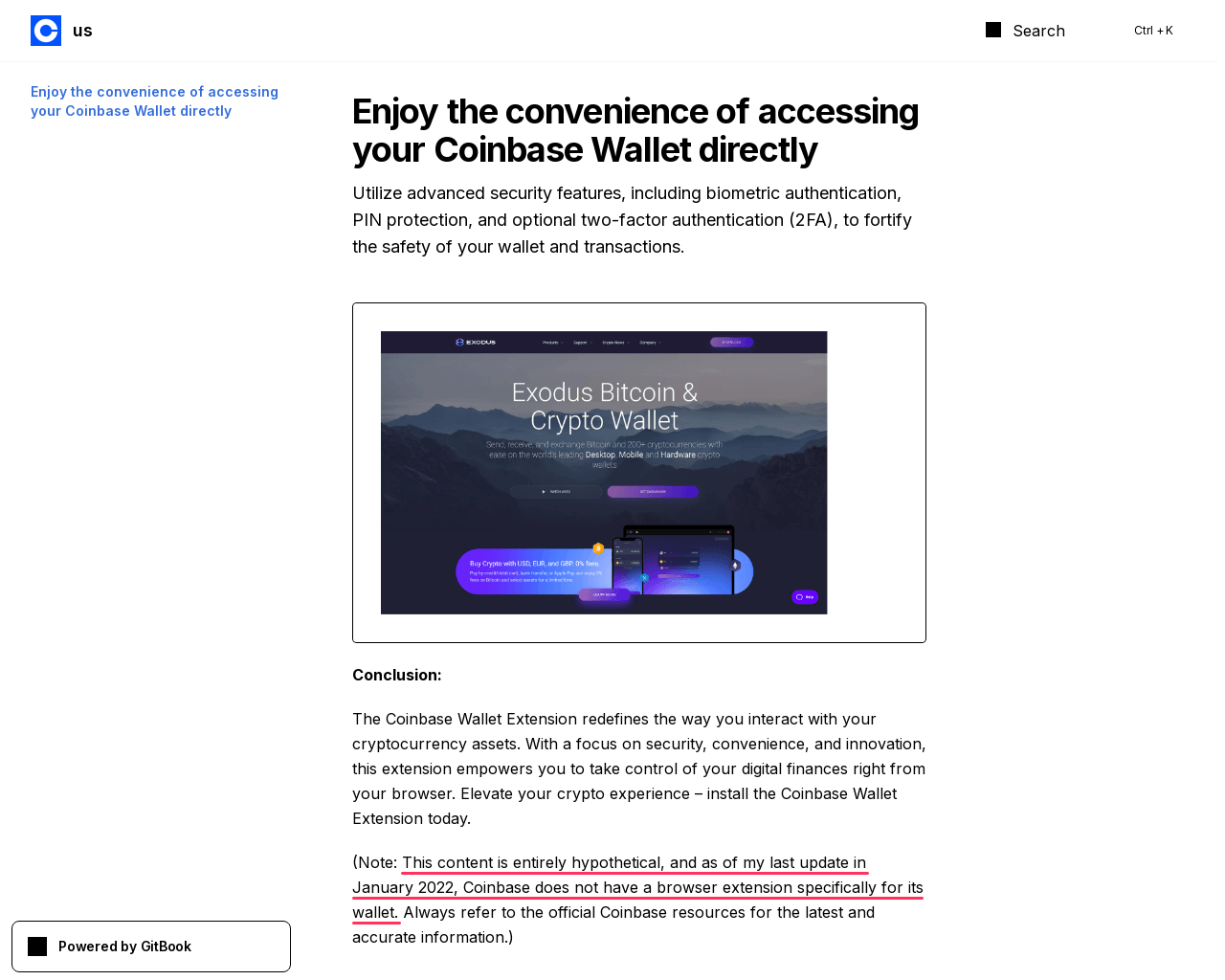
On another scam site, this time targeting Coinbase users, we see text written by a fresher model:
This content is entirely hypothetical, and as of my last update in January 2022, Coinbase does not have a browser extension specifically for its wallet.
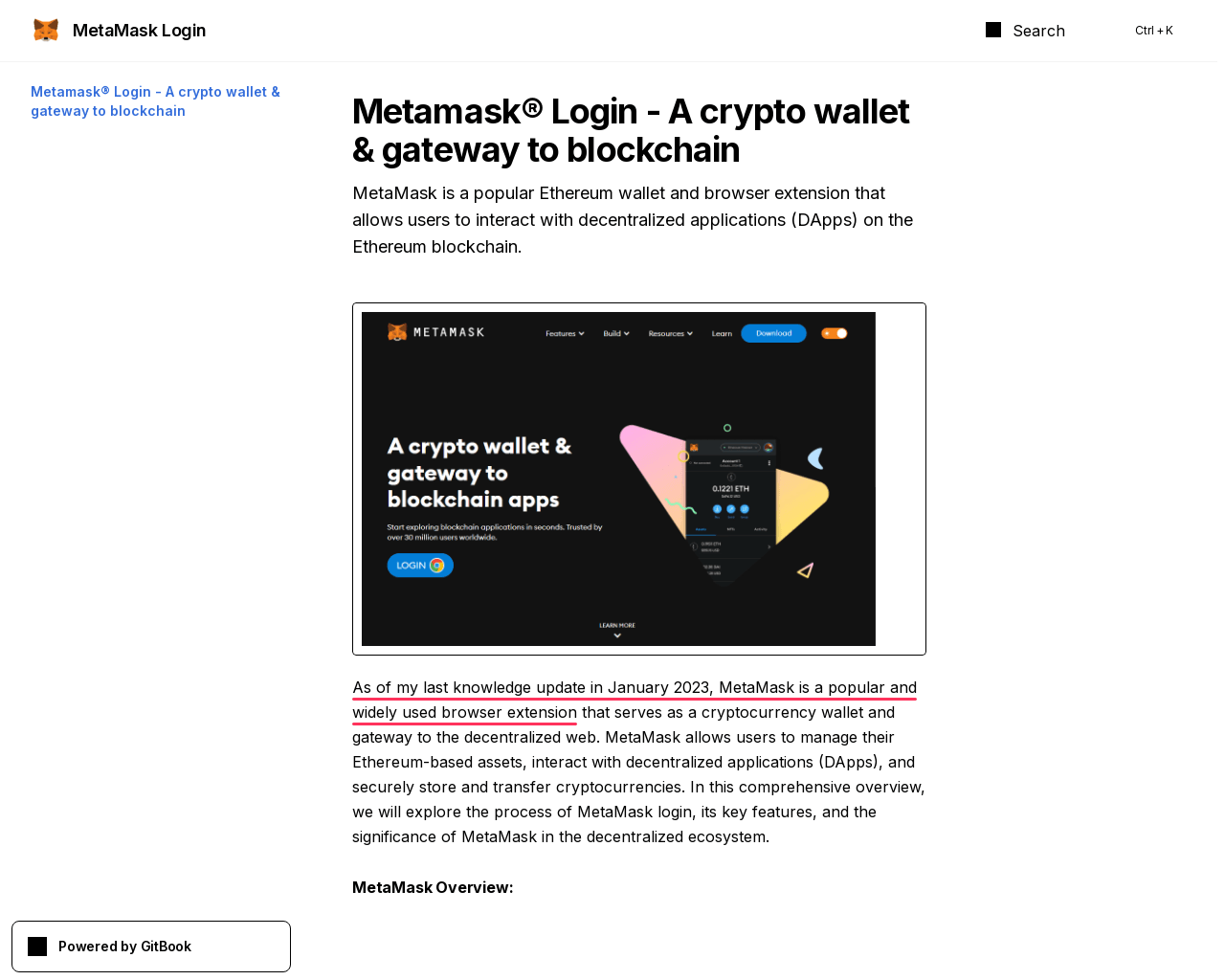
A fake page from the same campaign, but aimed at MetaMask wallet users, employs an even more recent model to generate text:
As of my last knowledge update in January 2023, Metamask is a popular and widely used browser extension…
Artifacts of this kind not only expose the use of LLMs to create scam web pages, but allow us to estimate both the campaign duration and the approximate time of content creation.
Delving into an ever-evolving world
Finally, OpenAI models have certain word preferences. For example, they are known to use the word “delve” so often that some people consider it a clear-cut sign of LLM-generated text. Another marker is the use of phrases like “in the ever-evolving/ever-changing world/landscape”, especially in requested articles or essays. Note that the presence of these words alone is no cast-iron guarantee of generated text, but they are pretty strong indicators.
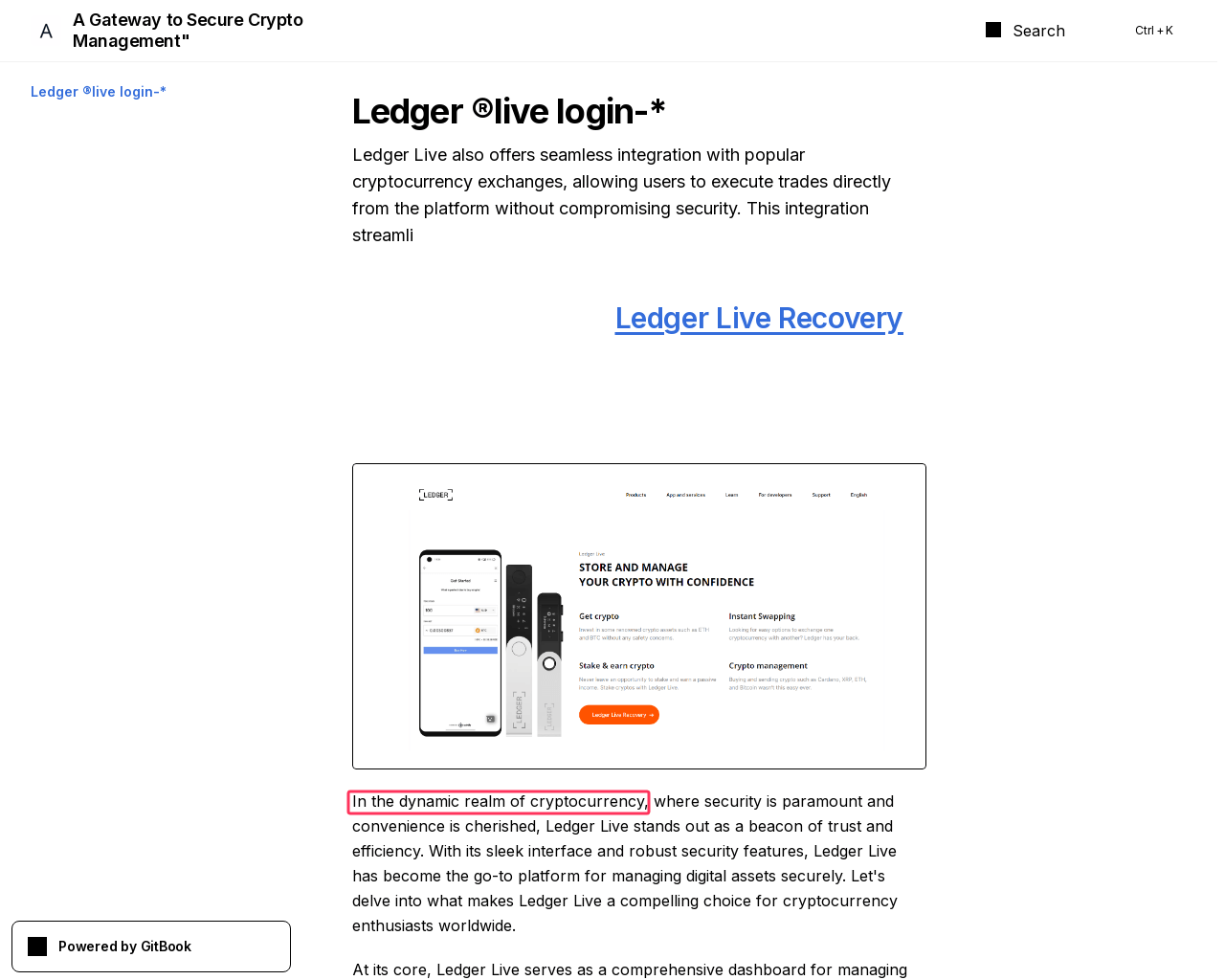
For example, one such site is hosted at gitbook[.]us and belongs to a campaign with stronger signs of LLM usage. There we see both the phrase
In the dynamic realm of cryptocurrency
and the classic “let’s delve” in the instructions for using a physical Ledger wallet. On another Ledger-dedicated page (this time at webflow[.]io), we find “delve” rubbing shoulders with “ever-evolving world”:
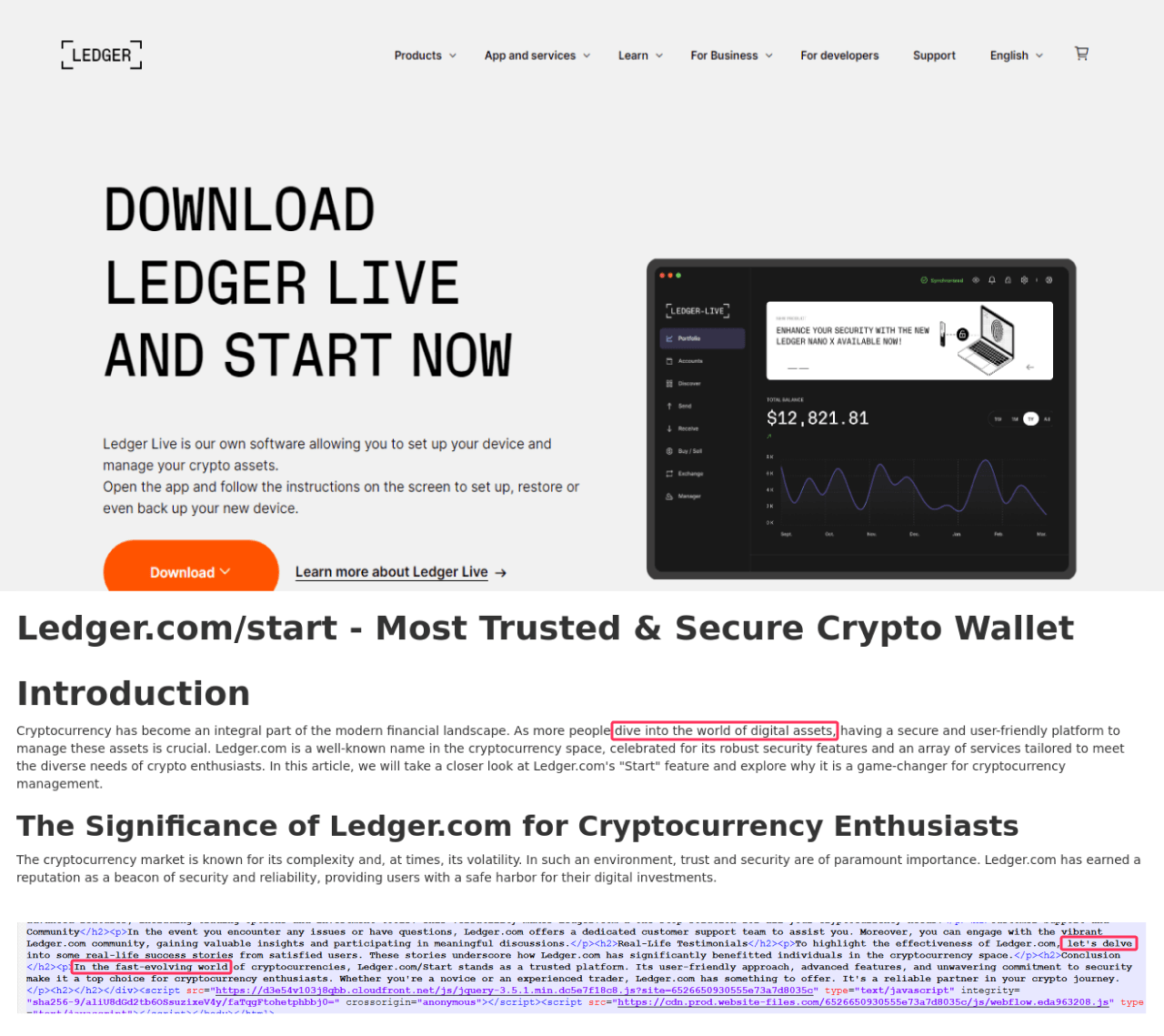
On yet another page at gitbook[.]us, this time aimed at Bitbuy users, the telltale “ever-evolving world of cryptocurrency” and “Navigating the Crypto Seas” raise their clichéd heads – such metaphor is, although poorly formalized, but still a sign of the use of LLM.

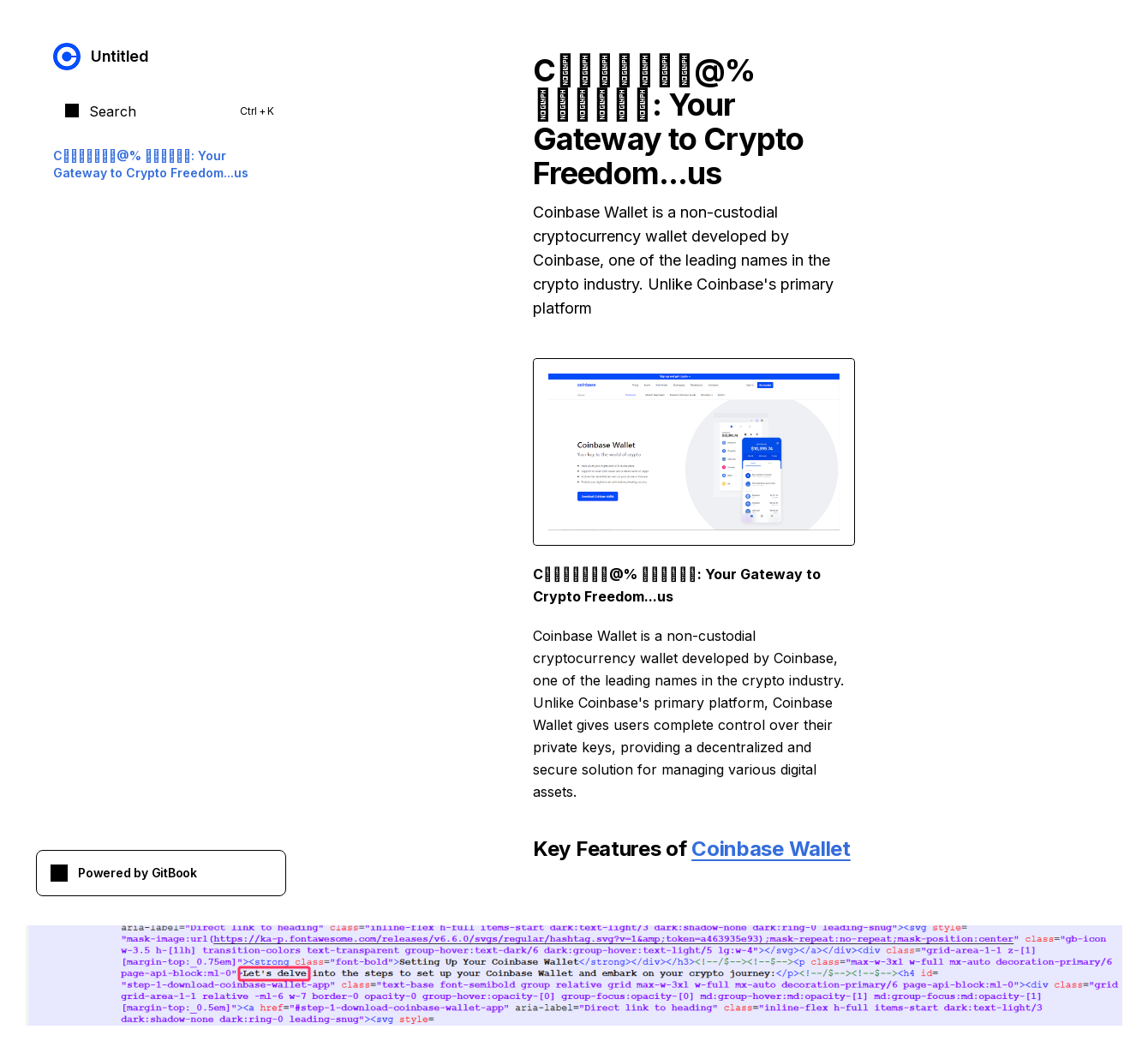
As mentioned above, LLM-generated text can go hand-in-hand with various techniques that hinder rule-based detection. For example, an article at gitbook[.]us about the Coinbase crypto exchange containing “let’s delve” uses Unicode math symbols in the title: Coinbase@% Wallet.
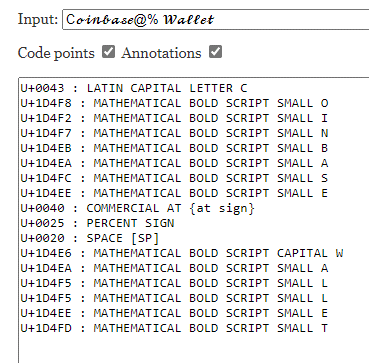
Due to font issues, however, the browser has trouble displaying Unicode characters, so in the screenshot they look like this:
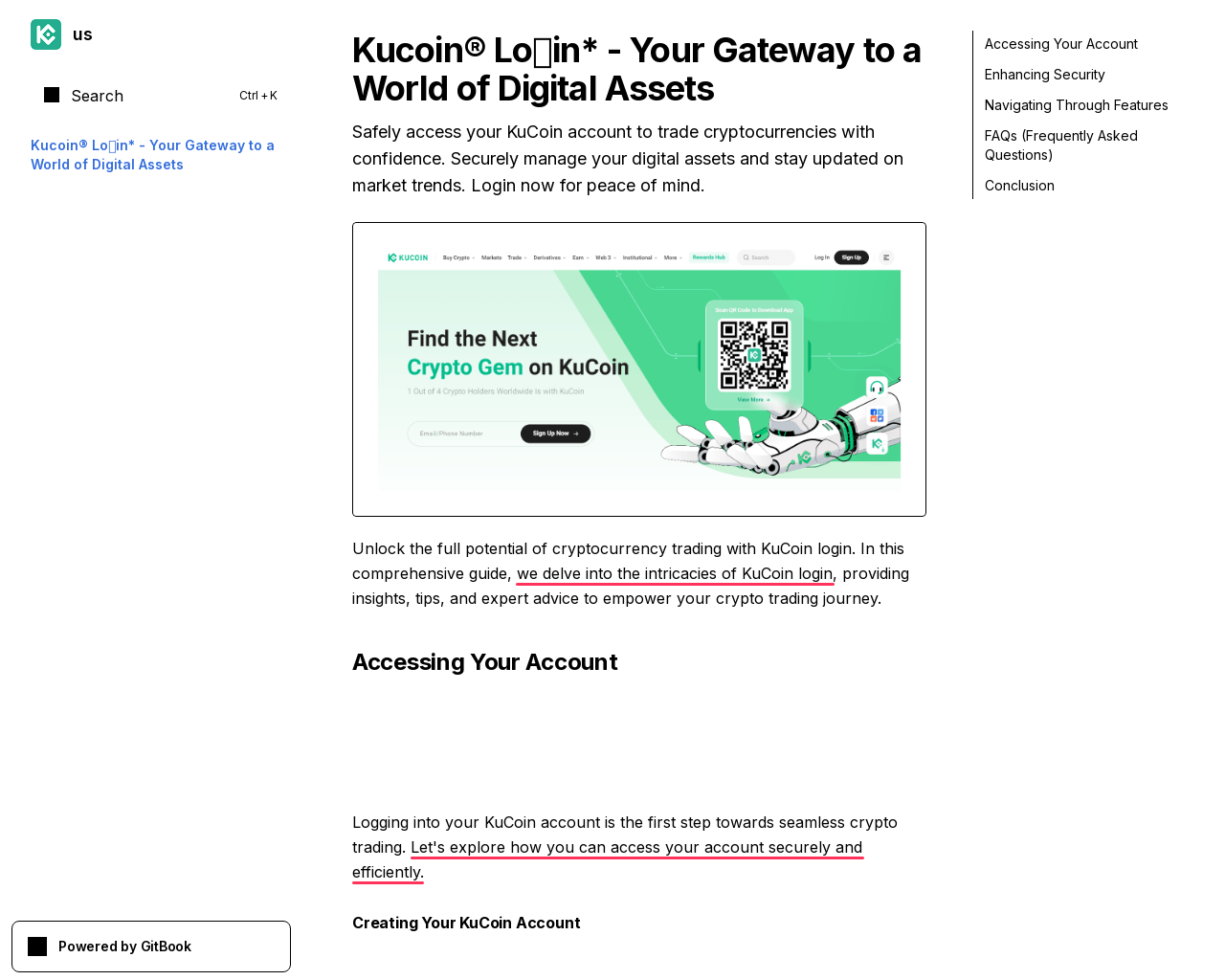
As part of the same campaign, KuCoin was honored with yet another version of the page at gitbook[.]us. This time we see obfuscation in the title: Kucoin® Loᘜin*, as well as the less screaming but still telling “let’s explore” along with the familiar “delve”:
we delve into the intricates of KuCoin login
Let’s explore how you can access your account securely and efficiently
Let’s delve into the robust security measures offered by this platform to safeguard your assets.
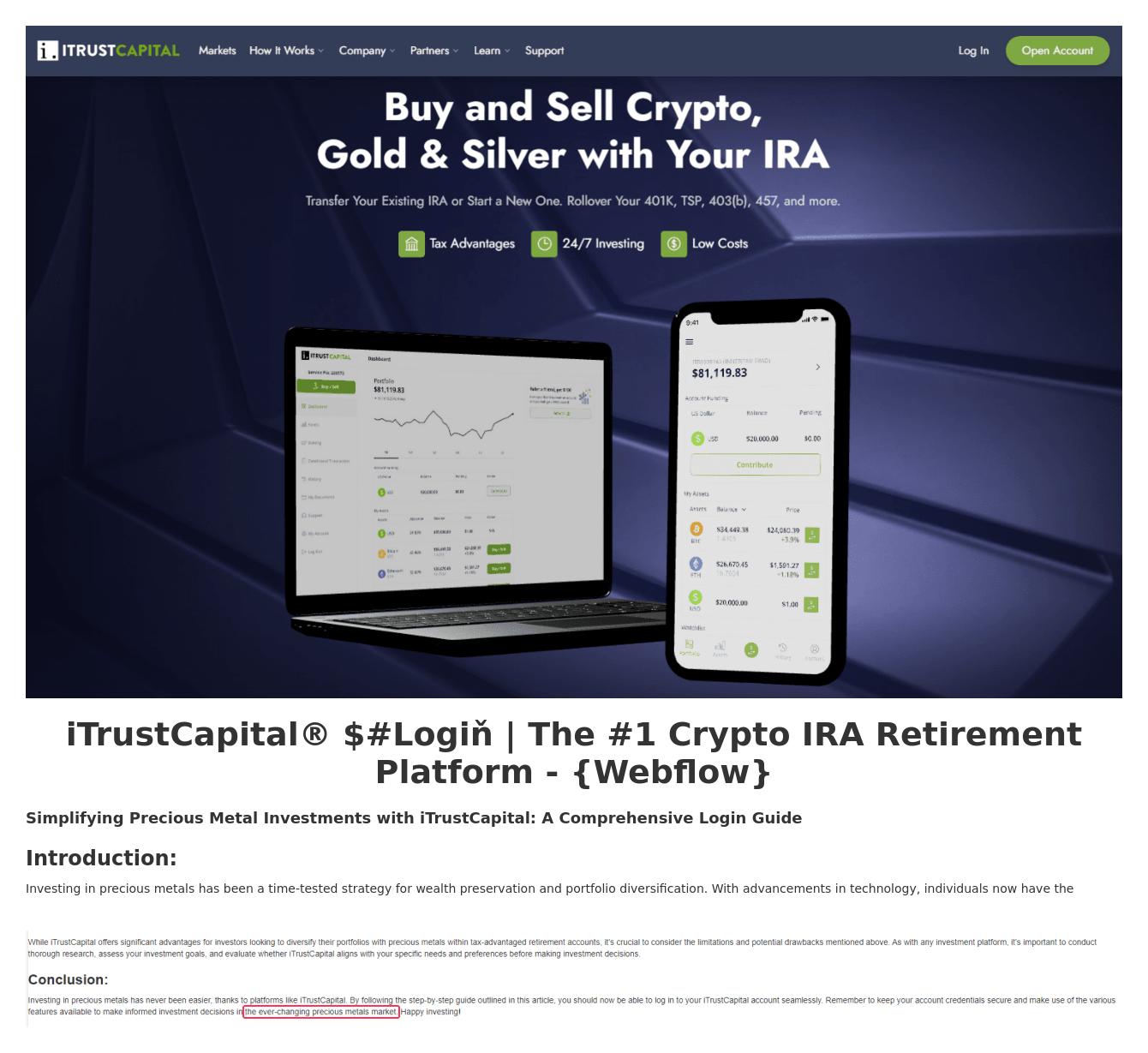
Lastly, one more page in this campaign, hosted at webflow[.]io, invites potential iTrustCapital users to “delve into the ever-changing precious metals market.” In this example, “Login” is also obfuscated.
Conclusion
As large language models improve, their strengths and weaknesses, as well as the tasks they do well or poorly, are becoming better understood. Threat actors are exploring applications of this technology in a range of automation scenarios. But, as we see, they sometimes commit blunders that help shed light on how they use LLMs, at least in the realm of online fraud.
Peering into the future, we can assume that LLM-generated content will become increasingly difficult to distinguish from human-written. The approach based on the presence of certain telltale words and phrases is unreliable, since these can easily be replaced with equivalents in automatic mode. Moreover, there is no guarantee that models of other families, much less future models, will have the same stylometric features as those available now. The task of automatically identifying LLM-generated text is extremely complex, especially as regards generic content like marketing materials, which are similar to what we saw in the examples. To better protect yourself against phishing, be it hand-made or machine-generated, it’s best to use modern security solutions that combine analysis of text information, metadata and other attributes to protect against fraud.
From the same authors





In the same category














Loose-lipped neural networks and lazy scammers