

Authors
Security operations centers (SOCs) exist to protect organizations from cyberthreats by detecting and responding to attacks in real time. They play a crucial role in preventing security breaches by detecting adversary activity at every stage of an attack, working to minimize damage and enabling an effective response. To accomplish this mission, SOC operations can be broken down into four operating phases:
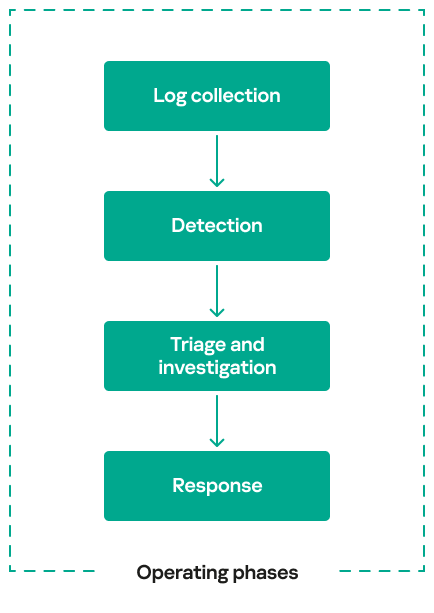
Each of these operating phases has a distinct role to play, and well-defined processes or procedures ensure a seamless handover of findings from one phase to the next. In practice, SOC processes and procedures at each operational phase often require continuous improvement over time.
Assessment observations: Common SOC issues
During our involvement in SOC technical assessments, adversary emulations, and incident response readiness projects across different regions, we evaluated each operating phase separately. Based on our assessments, we observed common challenges, weak practices, and recurring issues across these four key SOC capabilities.
Log collection
There are three main issues we have observed at this stage:
- Lack of visibility coverage based on the MITRE DETT&CT framework – customers do not practice maintaining a visibility coverage matrix. Instead, they often maintain log source data as an Excel or similar spreadsheet that is not easily tracked. This means they don’t have a systematic approach to what data they are feeding into the SIEM and which TTPs can be detected in their environment. And in most cases, maintaining a continuous visibility matrix is also a challenge because log sources may disappear over time for a variety of reasons: agent termination, changes in log destination settings, device (e.g., firewall) replacement. This only leads to the degradation of the log visibility matrix.
- Inefficient use of data for correlation – in many cases, relevant data is available to detect threats, but there are no correlation rules in place to leverage it for threat detection.
- Correlation exists, but lacks the necessary data fields – while some rule sets are properly configured with the right logic to detect threats, the required data fields from log sources are missing, preventing the rules from being triggered. This critical issue can only be detected through a data quality assessment.
Detection
At this stage, we have seen the following issues during assessment procedures:
- Over-reliance on vendor-provided rules – many customers rely heavily on the default rule sets in their SIEM and only tune them when alerts are triggered. Since the default content is not optimized, it often generates thousands of alerts. This reactive approach leads to excessive alert fatigue, making it difficult for analysts to focus on truly meaningful alerts.
- Lack of detection alignment with the threat profile – the absence of a well-defined organizational threat profile prevents customers from focusing on the threats that are most likely to target them. Instead, they adopt a scattered approach to detection, like shooting in the dark rather than prioritizing relevant threats.
- Poor use of threat intelligence feeds – we have encountered cases where endpoint logs do not contain file hash data. The log sources only provide filenames or file paths, but not the actual hash values, making it difficult for the SOC to correlate threat intelligence (TI) feeds that rely on file hashes. As a result, TI feeds are not operational because the required data field is not ingested into the SIEM.
- Analytics deployment errors – one of the most challenging issues we see is when a well-designed detection rule is deployed incorrectly, causing threat detection to fail despite having the right analytics in place. We have found that there is no structured process for reviewing and validating rule deployments.
Triage and investigation
The most typical issues at this stage are:
- Lack of a documented triage procedure – analysts often rely on generic, high-level response playbooks sourced from the internet, especially from unreliable sources, which slows or hinders the process of qualifying alerts as potential incidents. Without a structured triage procedure, they spend more time investigating each case instead of quickly assessing and escalating threats.
- Unattended alerts – we also observed that many alerts were completely ignored by analysts. This likely stems from either a lack of skill in linking multiple alerts into a single incident, or analysts being swamped with high-severity alerts, causing them to overlook other relevant alerts.
- Difficulty in correlating alerts – as noted in the previous observation, one of the biggest challenges is linking related alerts into a single incident. The lack of alert correlation makes it harder to see the full attack pattern, leading to disorganized alert diagnosis.
- Default use of alert severity – SIEM default rules don’t take into account the context of the target system. Instead, they rely on the default severity in the rule, which is often set randomly or based on an engineer’s opinion without a clear process. This lack of context makes it harder to investigate and properly assess alerts.
Response
The challenges of the final operating phase are most often derived from the issues encountered in the previous stages.
- Challenges in incident scoping – as mentioned earlier, the inability to properly correlate alerts leads to a fragmented understanding of attack patterns. This makes it difficult to see the bigger picture, resulting in inefficient incident handling and misjudged response efforts.
- Increase in unnecessary escalations – this issue is particularly common in MSSP environments, where a lack of understanding of baseline behavior causes analysts to escalate benign cases. Without proper context, normal activities are mistaken for threats, resulting in wasted time and effort.
With these ongoing challenges, chaos will continue in SOC operations. As organizations adopt new security tools such as CASB and container security, both of which generate valuable detection data, and as digital transformation introduces even more technology, security operations will only become more complex, exacerbating these issues.
Taking the right and impactful approach
Enhancing SOC operations requires evaluating each operating phase from an investment perspective, with the detection phase having the greatest impact because it directly affects data quality, threat visibility, incident response efficiency, and the overall effectiveness of the SOC analyst. Investing in detection directly influences all the other operating phases, making it the foundation for improving all operating phases. The detection operating phase must be handled through a dedicated program that ensures log collection is purpose-driven, collecting only the data fields necessary for detection rather than unnecessarily driving up SIEM costs. This focused approach helps define what should be ingested into the SIEM while ensuring meaningful threat visibility.
Strengthening detection reduces false positives and false negatives, improves true positive rates, and enables the identification of attacker activity chains. A documented triage and investigation process streamlines the work of analysts, improving efficiency and reducing response time. Furthermore, effective incident scoping, guided by accurate detection of the cyber kill chain, enables a faster and more precise response. By prioritizing investment in detection and managing it through a structured approach, organizations can significantly improve SOC performance and resilience against evolving threats. This article focuses solely on SIEM-based detection management.
Detection engineering program
Before diving into the program-level approach, we will first present the detection engineering lifecycle that forms the foundation of the proposed program. The image below shows the stages of this lifecycle.
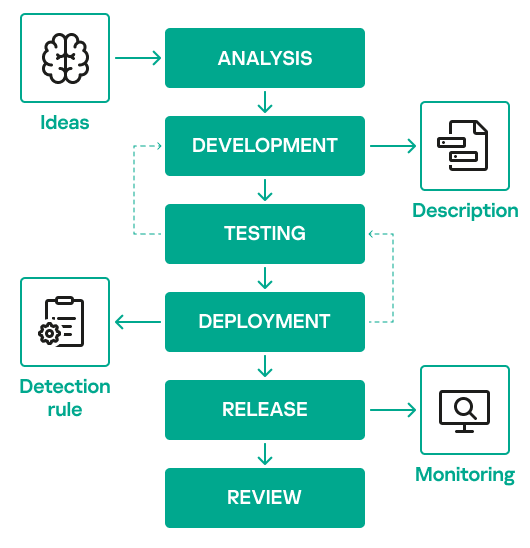
The detection engineering lifecycle shown here is typically followed when building detections, but its implementation often lacks well-defined processes or a dedicated team. A structured program must be put in place to ensure that the SOC’s investment and efforts in detection engineering are used efficiently.
When we talk about a program, it should be built on the following key elements:
- A dedicated team responsible for driving the program
- Well-defined processes and procedures to ensure consistency and effectiveness
- The right tools to integrate with workflows, facilitate output handovers, and enable feedback loops across related processes
- Meaningful metrics to measure the overall performance of the program.
We will discuss these performance measurement metrics in the final section of the article.
- Team supporting detection engineering program
The key idea behind having a dedicated team is to take full control of the detection engineering (DE) lifecycle, from analysis to release, and ensure accountability for the program’s success. In a traditional SOC setup, deployment and release are often handled by SOC engineers. This can lead to deployment errors due to potential differences in the data models used by DE and SOC teams (raw log data vs. SIEM-optimized data), as well as deployment delays due to the SOC team being overloaded with other tasks. This, in turn, can indirectly impact the work of the detection team. However, the one responsibility that does not fall under the DE team is log onboarding. Since this process requires coordination with other teams, it should continue to be managed by SOC engineers to keep the DE team focused on its core objectives.
The DE team should start with at least three key roles:

The size of the team depends on factors related to the program’s objectives. For example, if the goal is to build a certain number of detection rules per month, the number of detection engineers required will vary accordingly. Similarly, if a certain number of rules need to be tested and deployed within a week, the team size must be adjusted to meet that demand.
The Detection Engineering Lead should communicate with SOC leadership to set the right expectations by outlining what goals can realistically be achieved based on the size and capacity of the DE team. A dedicated Detection QA role can be established as the need for testing, deployment, and release of detections grows.
- Process and procedures
Well-defined workflows, supported by structured processes and procedures, must be established to streamline detection engineering operations. The following image illustrates the necessary processes and procedures, along with the roles responsible for executing each workflow:
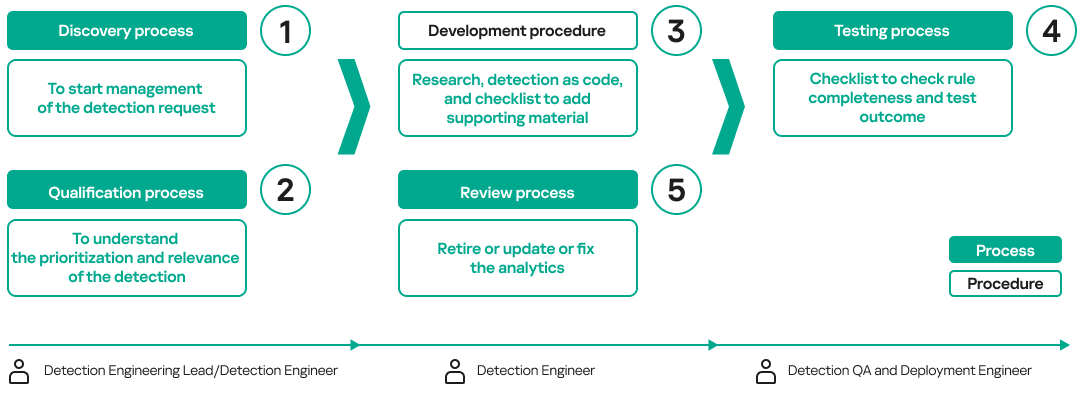
During the qualification process, the Detection Engineering Lead or Detection Engineer may discover that the data source needed to develop a detection is not available. In such cases, they should follow the log management process to request onboarding of the required data before proceeding with detection research and development. The testing process typically checks that the rule works by ensuring that the SIEM triggers an alert based on the required data fields.
Lastly, a validation process that is not part of the detection engineering lifecycle must be incorporated into the detection engineering program to assess its overall effectiveness. Ideally, this validation should be conducted by individuals outside the DE lifecycle or by an external service provider.
Proper planning is required that incorporates threat intelligence and an updated threat profile. In addition, the validation process should generate reports that outline:
- What is working well
- Areas that need improvement
- Detection gaps identified
- Tools
An essential element of the DE lifecycle is the use of tools to streamline processes and improve efficiency. Key tools include:
- Ticketing platform – efficiently manages workflows, tracks progress from ticket creation to closure, and provides time-based metrics for monitoring.
- Rules repository – platform for managing detection queries and code, supporting Detection-as-Code, using a unified rule format such as SIGMA, and implementing code development best practices in detection engineering, including features such as version control and change management.
- Centralized knowledge base – dedicated space for documenting detection rules, descriptions, research notes, and other relevant information. See the best practices section below for more details on centralized documentation.
- Communication platform – facilitates collaboration among DE team members, integrates with the ticketing system, and provides real-time notification of ticket status or other issues.
- Lab environment – virtualized setup, including SIEM and relevant data sources, tools to simulate attacks for testing purposes. The core function of the lab is to test detection rules prior to release.
Best practices in detection engineering
Several best practices can significantly enhance your detection engineering program. Based on our experience, implementing these best practices will help you effectively manage your rule set while providing valuable support to security analysts.
- Rule naming convention
When developing analytics or a rule, adhering to a proper naming convention provides a concrete framework. A rule name like “Suspicious file drop detected” may confuse the analyst and force them to dig deeper to understand the context of the alert that was triggered. It would be better to give a rule a name that provides complete context at first glance, such as “Initial Access | Suspicious file drop detected in user directory | Windows – Medium”. This example makes it easy for the analyst to understand:
- At what stage of the attack the rule is triggered. In this case, it is Initial Access as per MITRE / Kill Chain Model.
- Where exactly the file was dropped. In this case, the user directory was the target, which may mean that this probably involved user interaction, which is another sign that the attack was probably detected at an early stage.
- What platform was attacked. In this case, it is Windows, which can help the analyst to quickly find the machine that triggered the alert.
- Lastly, an alert priority can be set, which helps the analyst to prioritize accordingly. For this to work properly, SIEM’s priority levels should be aligned with the rule priorities defined by the detection engineering team. For example, a high priority in SIEM should correspond to a high-priority alert.
A consistent rule naming structure can help the detection engineering team to easily search, sort and manage existing rules, avoid creating duplicates with different names, etc.
The naming structure doesn’t necessarily have to look like the example above. The whole idea of this best practice is to find a good naming convention that not only helps the SOC analyst, but also makes managing detection rules easier and more convenient.
For example, while the rule name “Audit Log Deletion” gives a basic idea of what is happening, a more effective name would be:
|
1 |
[High] – Audit Log Deletion in Internal Server Farm – Linux - Defense Evasion (1070.002). |
This provides better context, making it much more useful to the SOC team, and more keywords for the DE team to find this particular rule or filter rules if necessary.
- Centralized knowledge base
Once a rule is created after thorough research, the detection team should manage it in a centralized platform (a knowledge base). This platform should not only store the rule name and logic, but also other key details. Important elements to consider:
- Rule name/ID/description – rule name, unique ID, and a brief description of the rule.
- Rule type/status – provides insight into the rule type (static, correlated, IoC-based, etc.) and the status (experimental, stable, retired, etc.).
- Severity and confidence – seriousness of the threat triggering this rule and the likelihood of a true positive.
- Research notes – possible public links, threat reports, used as a basis for creating the rule.
- Data components used to detect the behavior – list of source and data fields used to detect activity.
- Triage steps – provides steps to investigate the alert.
- False positives – provides options where the alert could show false positive behavior.
- Tags (CVE, Actors, Malware, etc.) – provide more context if the detection is linked to a behavior or artifact, specific to any APT group, or malware.
Make sure this centralized documentation is accessible to all SOC analysts.
- Contextual tagging
As covered in the previous best practice, tags provide a great value in understanding the attack chain. That’s why we want to highlight them as a separate best practice.

The tags attached to the above detection rule are the result of the research done on the behavior of the attack when writing the detection rule. They help the analyst gain more context at the time the rule is triggered. In the example above, the analyst may suspect a potential initial access attempt related to QakBot or Black Basta ransomware. This also helps in reporting to security leadership that the SOC team successfully detected the initial ransomware behavior and was able to thwart the attack in the early stages of the kill chain.
- Triage steps
A good practice is to include triage (or investigation steps) in detection rule documentation. Since the DE team has spent a lot of time understanding the threat, it is very important to document the precursors and possible next steps the attacker can take. The SOC analyst can quickly review these and provide incident qualification with confidence.
For the rule from the previous section, “Initial Access | Suspicious LNK files dropped in download folder | Windows – Medium”, the triage procedure is shown below.

MITRE has a project called the Technique Inference Engine, which provides a model for understanding other techniques an attacker is likely to use based on observed adversary behavior. This tool can be useful for both DE and SOC teams. By analyzing the attacker’s path, organizations can improve alert correlation and enhance scoping of incident/threats.
- Baselining
Understanding the infrastructure and its baseline operations is a must, as it helps reduce the false positive rate. The detection engineering team must learn the prevention policies (to de-prioritize detection if already remediated), learn about the technologies deployed in the infrastructure, understand the network protocols being used and user behavior under normal circumstances.
For example, to detect T1480.002: Execution Guardrails: Mutual Exclusion sub-technique, MITRE recommends monitoring a “file creation” data component. According to the MITRE Data Sources framework, data components are possible actions with data objects and/or data objects statuses or parameters that may be relevant for threat detection. We discussed them in more detail in our detection prioritization article.

MITRE’s detection recommendation for T1480.002 sub-technique
A simple rule for detecting such activity is to monitor lock file creation events in the /var/run folder, which stores temporary runtime data for running services. However, if you have done the baselining and found that the environment uses containers that also create lock files to manage runtime operations, you can filter out container-linked events to avoid triggering false positive alerts. This filter is easy to apply, and overall detection can be improved by baselining the infrastructure you are monitoring.
- Finding the narrow corridors
Some indicators, such as file hashes or software tools are easy to change, while others are more difficult to replace. Detections based on such “narrow corridors” tend to have high true positive rates. To pursue this, detection should focus primarily on behavioral indicators, ensuring that attackers cannot easily evade detection by simply changing their tools or tactics. Priority should be given to behavior-based detection over tool-specific, software-dependent, or IoC-driven approaches. This aligns with the Pyramid of Pain model, which emphasizes detecting adversaries based on their tactics, techniques, and procedures (TTPs) rather than easily replaceable indicators. By prioritizing common TTPs, we can effectively identify an adversary’s modus operandi, making detection more resilient and impactful.
- Universal rules
When planning a detection program from scratch, it is important not to ignore the universal threat detection rules that are mostly available in SIEM by default. Detection engineers should operationalize them as soon as possible and tune them according to feedback received from SOC analysts or what they have learned about the organization’s infrastructure during baselining activity.
Universal rules generally include malicious behavior associated with applications, databases, authentication anomalies, unusual remote access behavior, and policy violation rules (typically to monitor compliance requirements).
Some examples include:
- Windows firewall settings modification detected
- Use of unapproved remote access tools
- Bulk failed database login attempts
Performance measurement
Every investment needs to be justified with measurable outcomes that demonstrate its value. That is why communicating the value of a detection engineering program requires the use of effective and actionable metrics that demonstrate impact and alignment with business objectives. These metrics can be divided into two categories: program-level metrics and technical-level metrics. Program-level metrics signal to security leadership that the program is well aligned with the company’s security objectives. Technical metrics, on the other hand, focus on how operational work is being carried out to maximize the detection engineering team’s operational efficiency. By measuring both program-level metrics and technical-level metrics, security leaders can clearly show how the detection engineering program supports organizational resilience while ensuring operational excellence.
Designing effective program-level metrics requires revisiting the core purpose for initiating the program. This approach helps identify metrics that clearly communicate success to security leadership. There are three metrics that can be very effective to measure the success at program level.
- Time to Detect (TTD) – this metric is calculated as the time elapsed from the moment an attacker’s initial activity is observed until the time it is formally detected by the analyst. Some SOCs consider the time the alert is triggered on the SIEM as the detection time, but that is not really an actionable metric to consider. The time the alert is converted into a potential incident is the best option to consider for detection time by SOC analysts.
![]()
Although the initial detection of activity occurs at t1 (alert triggered), when malicious activity occurs, a series of events must be analyzed before qualifying the incident. This is why t3 is required to correctly qualify the detection as a potential threat. Additional metrics such as time to triage (TTT), which establishes how long it takes to qualify the incident, and time to investigate (TTI), which describes how long it takes to investigate the qualified incident, can also come in handy.
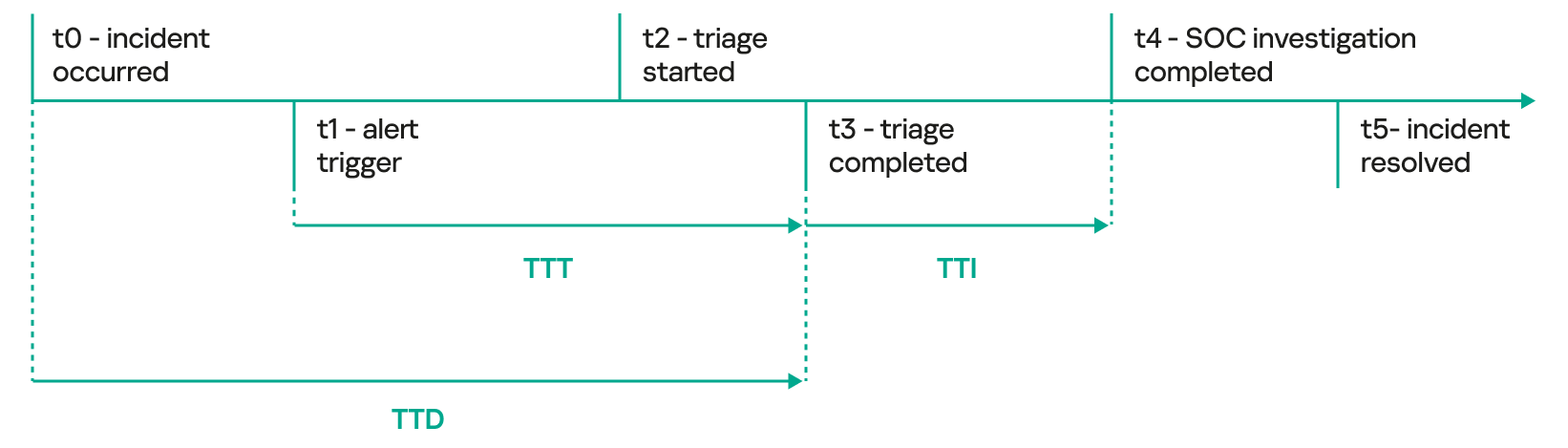
Time to detect compared to time to triage and time to investigate metrics
- Signal-to-Noise Ratio (SNR) – this metric indicates the effectiveness of detection rules by measuring the balance between relevant and irrelevant information. It compares the number of true positive detections (correct alerts for real threats) to the number of false positives (incorrect or misleading alerts).
![]()
Where:
True positives: instances where a real threat is correctly detected
False positives: incorrect alerts that do not represent real threats
A high SNR indicates that the system is generating more meaningful alerts (signal) compared to noise (false positives), thereby enhancing the efficiency of security operations by reducing alert fatigue and focusing analysts’ attention on genuine threats. Improving SNR is crucial to maximizing the performance and reliability of a detection program. SNR directly impacts the amount of SOC analyst effort spent on false positives, which in turn influences alert fatigue and the risk of professional burnout. Therefore, it is a very important metric to consider.
- Threat Profile Alignment (TPA) – this metric evaluates how well detections are aligned with known adversarial tactics, techniques, and procedures (TTPs). This metric measures this by determining how many of the identified TTPs are adequately covered by unique detections (unique data components).
![]()
Total TTPs identified – this is the number of known adversarial techniques relevant to the organization’s threat model, typically derived from cyber threat intelligence threat profiling efforts
Total TTPs covered with at least three unique detections (where possible) – this counts how many of the identified TTPs are covered by at least three distinct detection mechanisms. Having multiple detections for a given TTP enhances detection confidence, ensuring that if one detection fails or is bypassed, others can still identify the activity.
Team efforts supporting the detection engineering program must also be measured to demonstrate progress. These efforts are reflected in technical-level metrics, and monitoring these metrics will help justify team scalability and address productivity challenges. Key metrics are outlined below:
- Time to Qualify Detection (TTQD) – this metric measures the time required to analyze and validate the relevance of a detection for further processing. The Detection Engineering Lead assesses the importance of the detection and prioritizes it accordingly. The metric equals the time that has elapsed from when a ticket is raised to create a detection to when it is shortlisted for further research and implementation.
![]()
- Time to Create Detection (TTCD) – this tracks the amount of time required to design, develop and deploy a new detection rule. It highlights the agility of detection engineering processes in responding to evolving threats.
![]()

- Detection Backlog – the backlog refers to the number of pending detection rules awaiting review or consideration for detection improvement. A growing backlog might indicate resource constraints or inefficiencies.
- Distribution of Rules Criticality (High, Medium, Low) – this metric shows the proportion of detection rules categorized by their criticality level. It helps in understanding the balance of focus between high-risk and lower-risk detections.
- Detection Coverage (MITRE) – detection coverage based on MITRE ATT&CK indicates how well the detection rules cover various tactics, techniques, and procedures (TTPs) in the MITRE ATT&CK framework. It helps identify coverage gaps in the defense strategy. Tracking the number of unique detections that cover each specific technique is highly recommended, as it provides visibility into the threat profile alignment – a program level metric. If unique detections are not being built to detect gaps and the coverage is not increasing over time, it indicates an issue in the detection qualification process.
- Share of Rules Never Triggered – this metric tracks the percentage of detection rules that have never been triggered since their deployment. It may indicate inefficiencies, such as overly specific or poorly implemented rules, and provides insight for rule optimization.
There are other relevant metrics, such as the proportion of behavior-based rules in the total set. Many more metrics can be derived from a general understanding of the detection engineering process and its purpose to support the DE program. However, program managers should focus on selecting metrics that are easy to measure and can be calculated automatically by available tools, minimizing the need for manual effort. Avoid using an excessive number of metrics, as this can lead to a focus on measurement only. Instead, prioritize a few meaningful metrics that provide valuable insight into the program’s progress and efforts. Choose wisely!
Streamlining detection engineering in security operation centers
From the same authors

In the same category















Foaud
It is core issue of a SOC. Unfortunately, not many article or public guidance for this critical topic. Excellent work securelist!